Home › Synthetic Data and Anonymized Data: Which is right for you?
Synthetic Data and Anonymized Data: Which is right for you?
Uncover the hidden privacy risks in your test data. Data anonymization and masking are no longer enough to prevent re-identification attacks and costly data breaches. Discover how modern synthetic data generation offers a superior path to ironclad data privacy and compliance. This guide compares the two approaches, helping Data Architects and Compliance Officers choose the right strategy to protect sensitive original data, accelerate machine learning projects, and build resilient test data pipelines without compromising on data quality or security.

The High-Stakes Balancing Act of Modern Data
In today’s data-driven landscape, Data Architects and Compliance Officers face a relentless dual mandate. On one hand, they are tasked with unlocking the immense value within their organization’s data to fuel innovation, train powerful AI models, and sharpen their competitive edge. On the other, they must construct an impenetrable fortress around that same data, safeguarding it against catastrophic data breaches and ensuring unwavering compliance with a labyrinth of ever-stricter privacy regulations.
The use of production or original data for non-production activities like software development, testing, and analytics is no longer a viable option; it is a direct path toward regulatory violations and a prime target for a cyber security attack. This reality creates an urgent, non-negotiable need for test data that is both functionally realistic and completely secure. To solve this challenge, two dominant strategies have emerged:
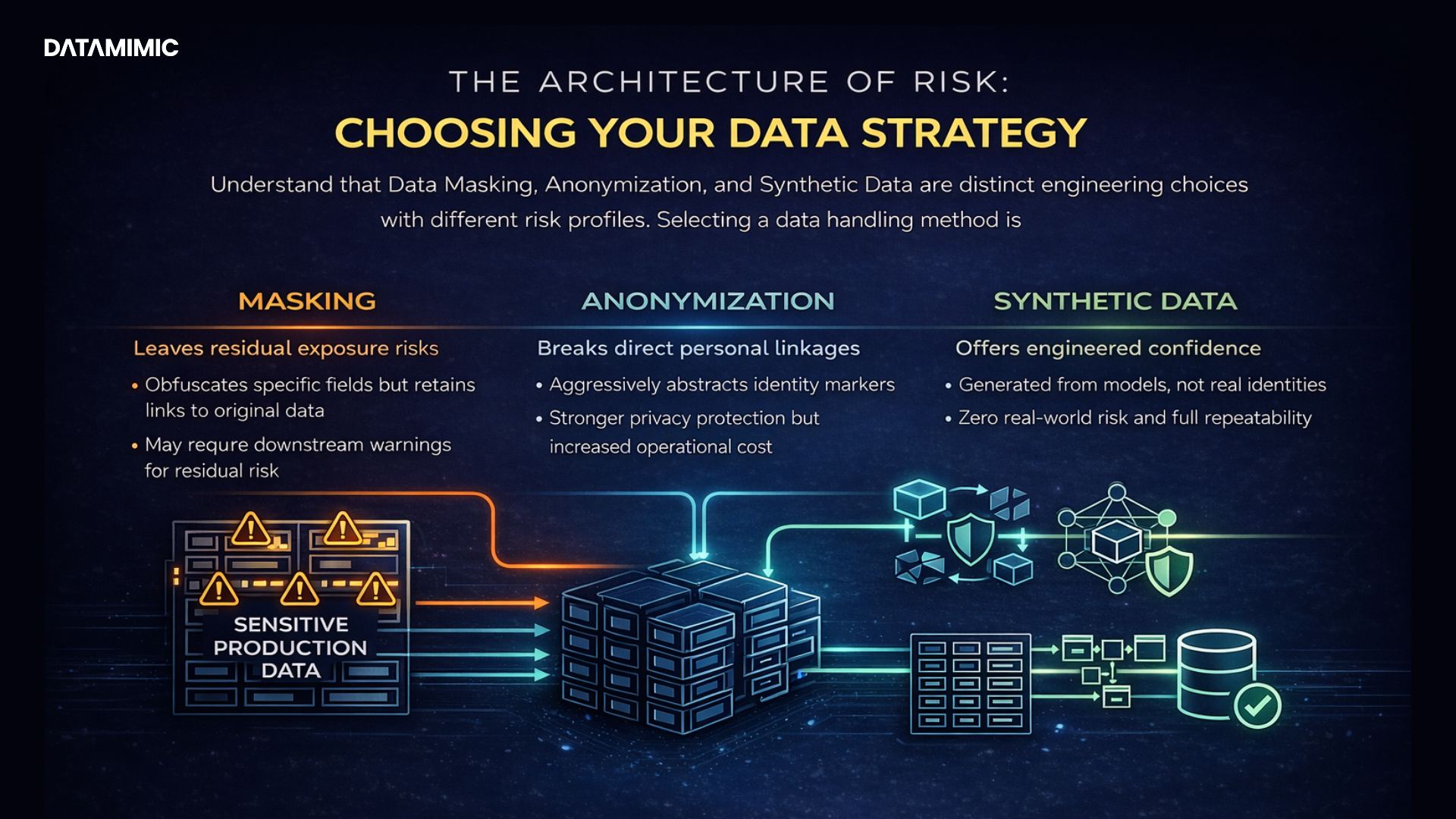
- Data Anonymization: The traditional approach of taking original data and attempting to surgically remove or obscure Personally Identifiable Information (PII).
-
Synthetic Data Generation: The modern approach of creating entirely new, artificial data that statistically mirrors the original data without containing a single trace of it.
This article serves as a definitive guide for data leaders, meticulously comparing these two methodologies across the critical axes of security, data utility, and operational agility. By understanding the profound differences between them, you can make the right strategic choice to advance your organization’s data protection and innovation goals.

Part 1: The Old Guard – Deconstructing Data Anonymization and Its Hidden Flaws
For years, Data Anonymization has been the default strategy for organizations needing to use sensitive information in non-production environments. The logic seems sound: take real data and make it safe. However, a closer examination reveals a methodology built on a fragile premise, one that carries significant and often underestimated risks.
What is Data Anonymization?
At its core, Data Anonymization is a type of information sanitization intended to protect data privacy by removing or modifying personal identifiable information from datasets. The ultimate goal is to sever the link between the data and the individual it describes, rendering them anonymous. This process falls under the broader umbrella of data obfuscation techniques, which employ a variety of methods to disguise data. The most common techniques include:
- Data Masking: This involves hiding sensitive data by replacing it with realistic but fictitious values. For example, a real name might be replaced with a fake one, or a Social Security Number might be replaced with a randomly generated nine-digit number that preserves the format. While effective at hiding direct identifiers, Data Masking is often an irreversible process designed to make reverse engineering impossible.
- Pseudonymization: A related but distinct technique, pseudonymization replaces private identifiers with reversible, non-sensitive placeholders or “pseudonyms”. This method is often used when there is a legitimate need to potentially re-link the data later under controlled conditions. It’s a critical distinction for compliance, as regulators in the European Union under GDPR often still consider pseudonymized data to be personal data, keeping it within the scope of strict data protection regulations.
- Other Techniques: A full suite of data anonymization tools may also employ methods like generalization (reducing the precision of data, like turning an age into an age range), swapping (shuffling attribute values between records), and perturbation (adding random noise to numerical data).
The Achilles' Heel: The Lingering Threat of a Re-identification Attack
Despite this arsenal of techniques, “anonymized” data is rarely ever truly anonymous. Its fundamental weakness—its Achilles’ heel—is the persistent and growing threat of a re-identification attack. This is the process where an adversary takes a de-identified dataset and, by cross-referencing it with other available information, successfully re-links the “anonymous” data back to specific individuals.
The vulnerability lies not in the direct identifiers that were removed, but in the “quasi-identifiers” that are left behind to maintain the data’s usefulness. These are pieces of information like ZIP code, date of birth, and gender that, on their own, do not identify a person. However, when combined, they can create a unique fingerprint. A 2019 study revealed the shocking scale of this problem, finding that 99.98% of Americans could be correctly re-identified in any dataset using just 15 demographic attributes.
This is not a theoretical threat. In a now-famous case, researcher Latanya Sweeney was able to re-identify the health records of the then-governor of Massachusetts, William Weld, by cross-referencing an “anonymized” public health dataset with a publicly available voter registration list. For a Compliance Officer, the implications are chilling. A successful re-identification attack is not a minor incident; it is a full-blown data breach. This single point of failure can trigger devastating consequences, including severe financial penalties under regulations like GDPR and HIPAA laws, a complete erosion of customer trust (trust issues), and permanent damage to the company’s reputation. Relying on traditional data masking tools is not a strategy of risk elimination; it is a constant, defensive battle against an ever-increasing threat.

Part 2: The New Paradigm – The Rise of High-Fidelity Synthetic Data
As the limitations of anonymization become clearer, a new paradigm has emerged, one that approaches the problem from a fundamentally different direction. Instead of trying to subtract risk from real data, synthetic data starts with zero risk and adds utility. This proactive approach is redefining what is possible for data protection and innovation.
What is Synthetic Data?
Synthetic data is artificially generated information that is not derived from real-world events. It is created by sophisticated algorithms that learn the statistical patterns, distributions, and correlations from a set of original data. The result is a brand-new dataset that looks, feels, and behaves just like the real thing but contains absolutely no original data or Personally Identifiable Information.
The critical differentiator is its foundation in “privacy by design.” Because synthetic data has no one-to-one mapping back to any real person, the concept of a re-identification attack becomes moot. It is not modified personal data; it is entirely new, safe information. This preemptively solves the core security problem, offering a robust and proactive solution for data privacy that legacy methods simply cannot match.
The Engine Room: Modern Synthetic Data Generation
It is crucial to distinguish modern synthetic data from simple mock data. While mock data consists of random, often nonsensical values used for basic unit tests, high-fidelity synthetic data is the product of advanced machine learning and artificial intelligence.
The data generation process is powered by a generative model, such as a Generative Adversarial Network (GAN) or a Variational Auto-Encoder (VAE). This data generation model is trained on the original data, allowing it to develop a deep mathematical understanding of its underlying structure. Once trained, this model can act as a factory, producing vast synthetic datasets on demand that faithfully replicate the statistical essence of the source. State-of-the-art platforms like DATAMIMIC leverage a model-based approach to synthetic data generation, which excels at creating realistic, interconnected test data that preserves complex business rules and maintains critical referential integrity across systems.
Beyond Privacy: The Architectural Advantage
The value of high-quality synthetic data extends far beyond compliance. For a Data Architect, it offers a powerful solution to some of the most persistent challenges in Test Data Management.
- Superior Data Quality and Coverage: Unlike anonymized data, which is limited to the events captured in the past, synthetic data can be engineered to have superior data quality. It can be intentionally designed to include edge cases and rare scenarios that might be missing from the production dataset, leading to more comprehensive and robust software testing.
- Maintaining Referential Integrity: One of the biggest failures of traditional data masking tools is their inability to consistently maintain relationships across complex, multi-table databases. A masked customer ID in one table may no longer link to the correct orders in another, rendering the test data useless. Advanced synthetic data generation platforms model these dependencies, ensuring that the generated synthetic test data maintains perfect referential integrity.
- Agility and Scale: In modern DevOps environments, development teams cannot afford to wait days or weeks for test data. Synthetic data provides on-demand, self-service access to safe, realistic data, integrating seamlessly into CI/CD and automated test data pipelines. This eliminates data provisioning bottlenecks and dramatically accelerates development cycles. For a Data Architect, synthetic data is no longer a “second-best” option; it is a superior form of test data that combines the realism of production with the safety and flexibility that original data can never provide.

Part 3: The Head-to-Head Showdown: A Guide for Decision-Makers
Choosing between Data Anonymization and synthetic data is a critical strategic decision. To make the right choice, it is essential to compare them directly across the dimensions that matter most to Data Architects and Compliance Officers: security, utility, and agility.
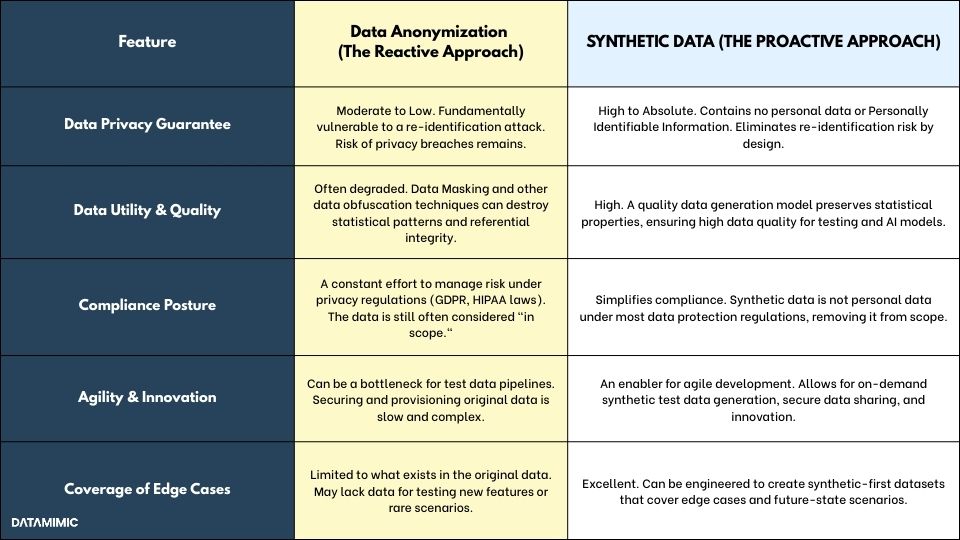
The Security & Compliance Verdict
For the Compliance Officer, the table illustrates a stark choice. Data Anonymization represents a strategy of perpetual risk management. It requires constant vigilance, ongoing assessments, and the implicit acceptance that a residual risk of re-identification always remains. This keeps the data “in scope” for auditors and regulators.
In contrast, synthetic data is a strategy of risk elimination. By generating data that contains no link to real individuals, it fundamentally removes the asset that needs protecting. This aligns perfectly with the principle of “privacy by design” championed by modern data protection regulations and simplifies the compliance burden for everything from health data lakes under HIPAA laws to consumer data under the GDPR in the European Union.
The Data Utility & Model Accuracy Verdict
For the Data Architect, the trade-off is equally clear. The very processes used in Data Anonymization, such as masking and generalization, can inadvertently destroy the subtle statistical patterns and correlations that make data valuable. This degradation of data quality can lead to inaccurate test results and poor model accuracy when the data is used to train machine learning models. High-fidelity synthetic data, generated from a sophisticated generative model, is designed specifically to preserve these complex relationships. This ensures that the synthetic test data behaves like real data, enabling accurate testing and the development of high-performing AI models without compromising on data privacy.
The Operational Agility Verdict
Ultimately, the choice impacts the entire software development lifecycle. Relying on masked production data creates dependencies and delays, forcing development teams into a holding pattern while they wait for data to be sourced, scrubbed, and provisioned. This friction is incompatible with the demands of modern agile and DevOps workflows. A modern Test Data Management Platform that provides on-demand synthetic data generation decouples development from production environments. It empowers teams with the synthetic test data they need, when they need it, fostering secure data sharing and accelerating innovation without the security overhead.
Part 4: Choosing Your Path – From Data Protection to Data Empowerment
The debate between synthetic data and Data Anonymization is more than a technical comparison; it signals a strategic inflection point in how modern enterprises approach data risk and value. The old paradigm involved locking original data in a secure vault and distributing heavily redacted, low-quality copies, hoping they were safe enough. This approach stifled innovation and offered a false sense of security against a potential cybersecurity attack.
The new paradigm is to create a Synthetic Data Vault—a secure, on-demand source of rich, realistic, and completely safe synthetic datasets that can be used to fuel innovation across the enterprise. The ultimate goal is no longer just data protection; it is data empowerment. It is about giving developers, testers, and data scientists the high-quality data they need to build the next generation of products and services, without ever having to compromise on data privacy or violate established privacy policies.
While legacy data masking tools and data anonymization tools were a necessary step in the evolution of data management, the rise of powerful artificial intelligence has made synthetic data generation the definitive solution for forward-thinking organizations. Enterprises that embrace a proactive, synthetic-first strategy with synthetic-first datasets are better positioned to innovate faster, build more reliable software, and earn lasting customer trust in an era defined by data breaches. Adopting a comprehensive Test Data Management Platform capable of creating high-quality synthetic data is the logical and necessary next step for any organization serious about both security and growth.

Alexander Kell
September 6, 2025
Contact Us Now
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly