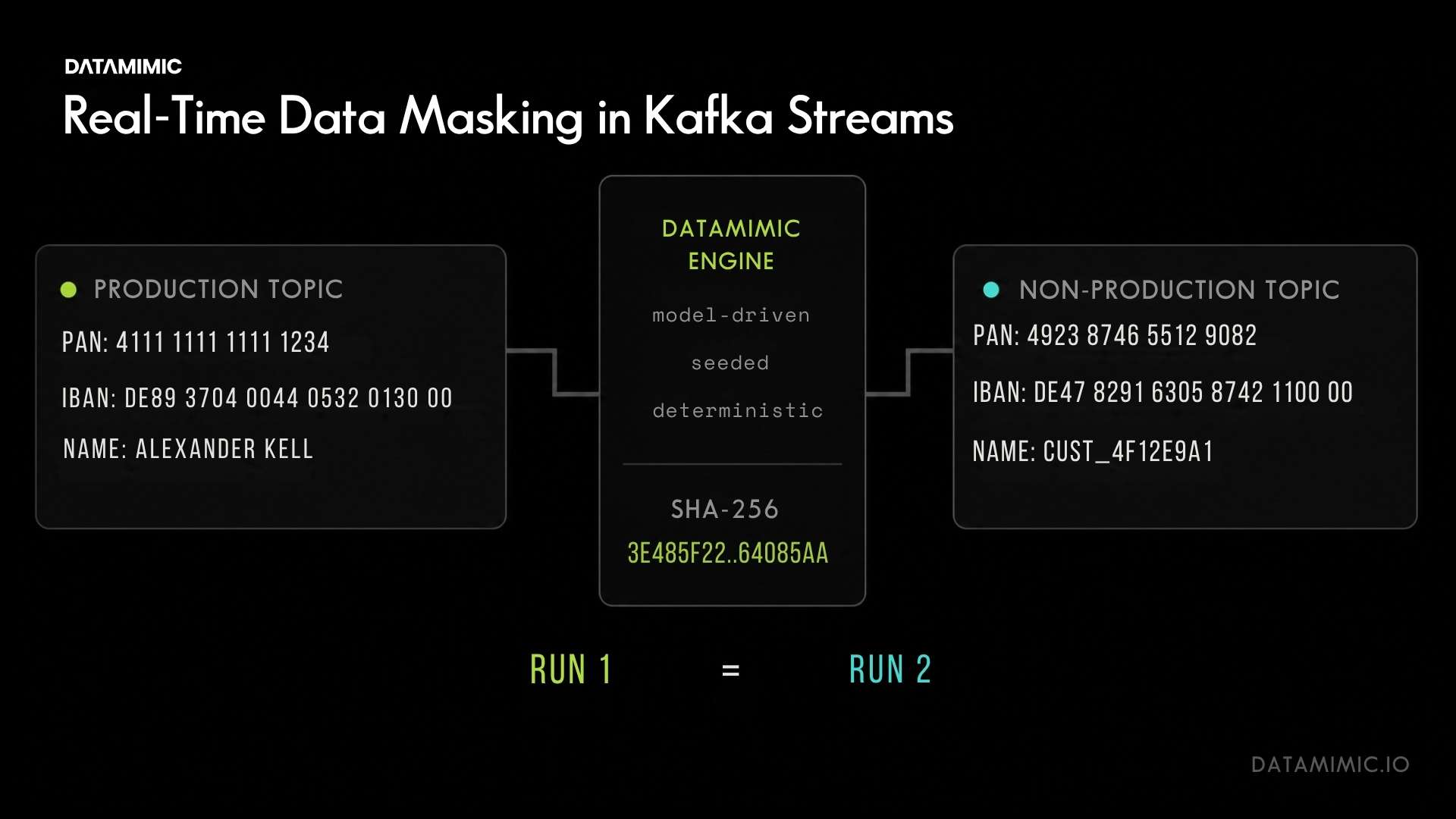
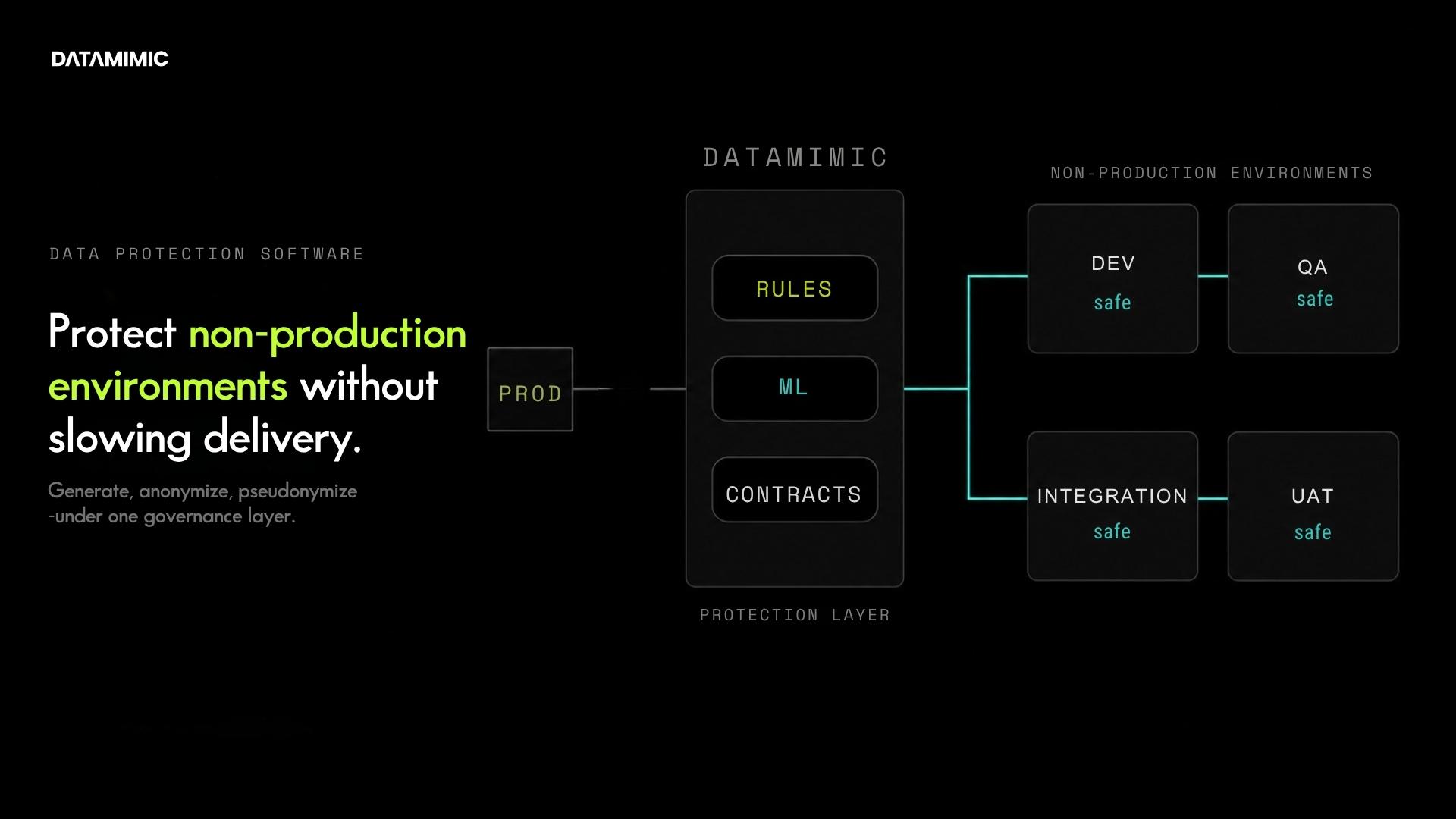
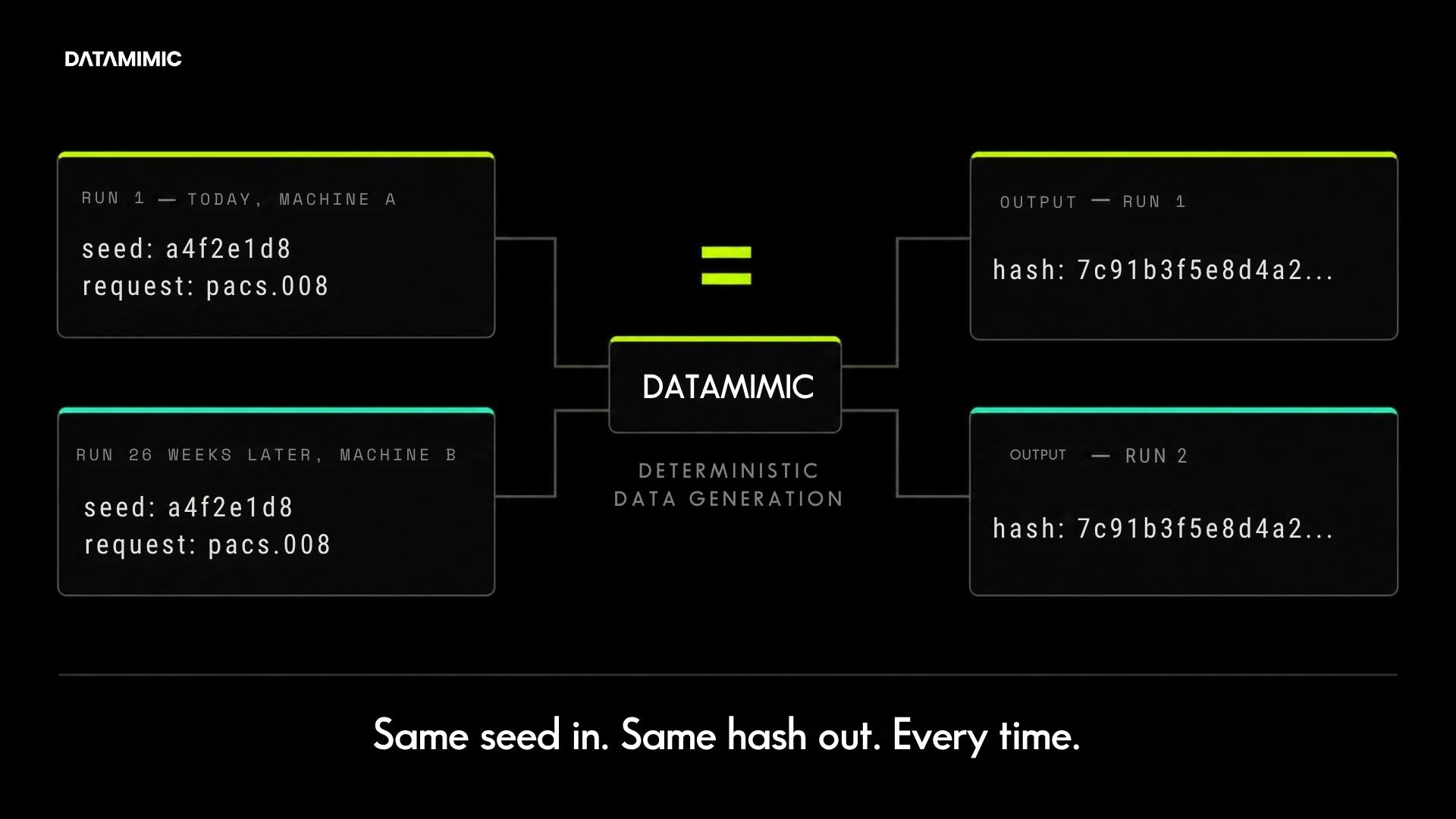
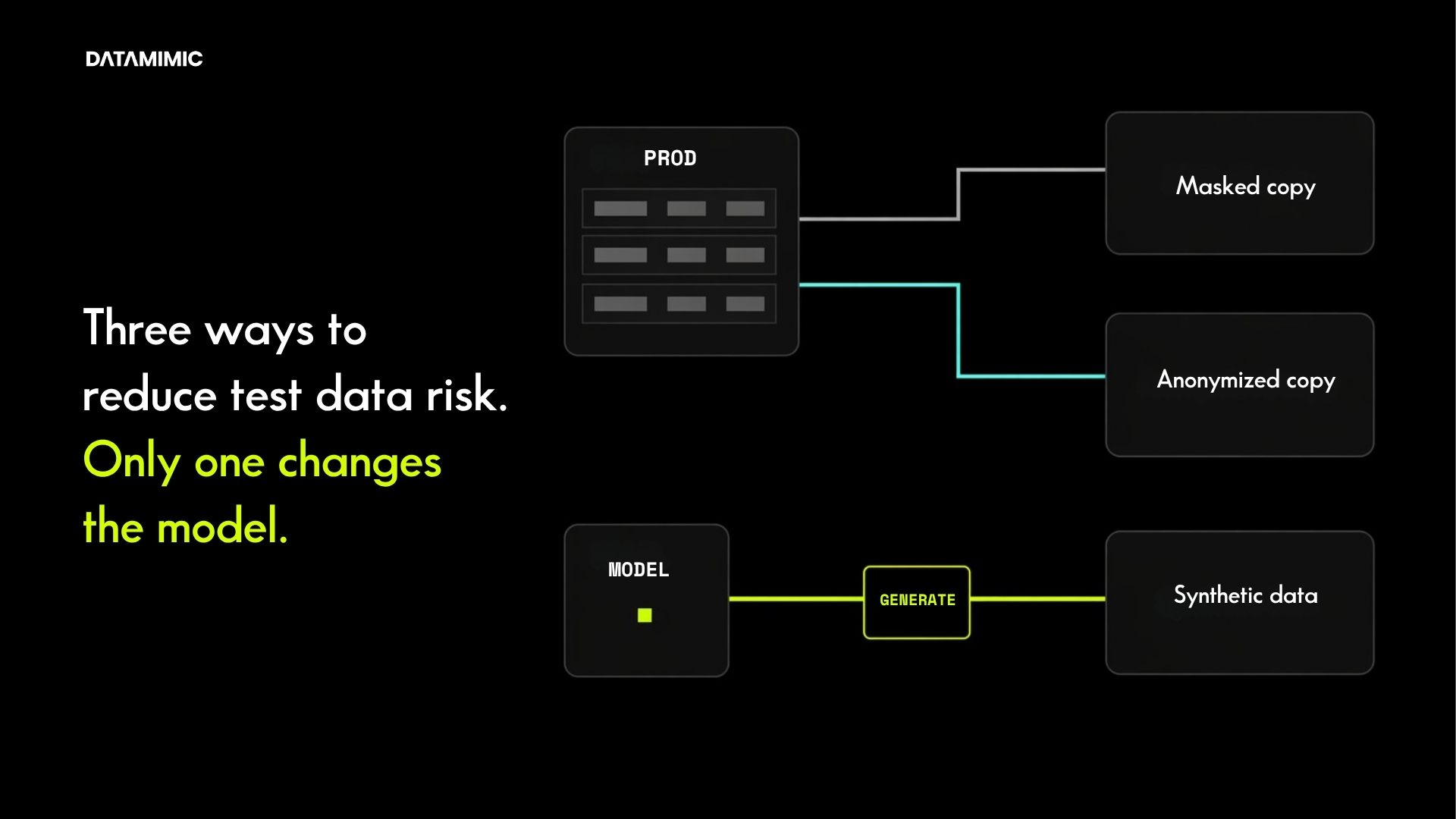
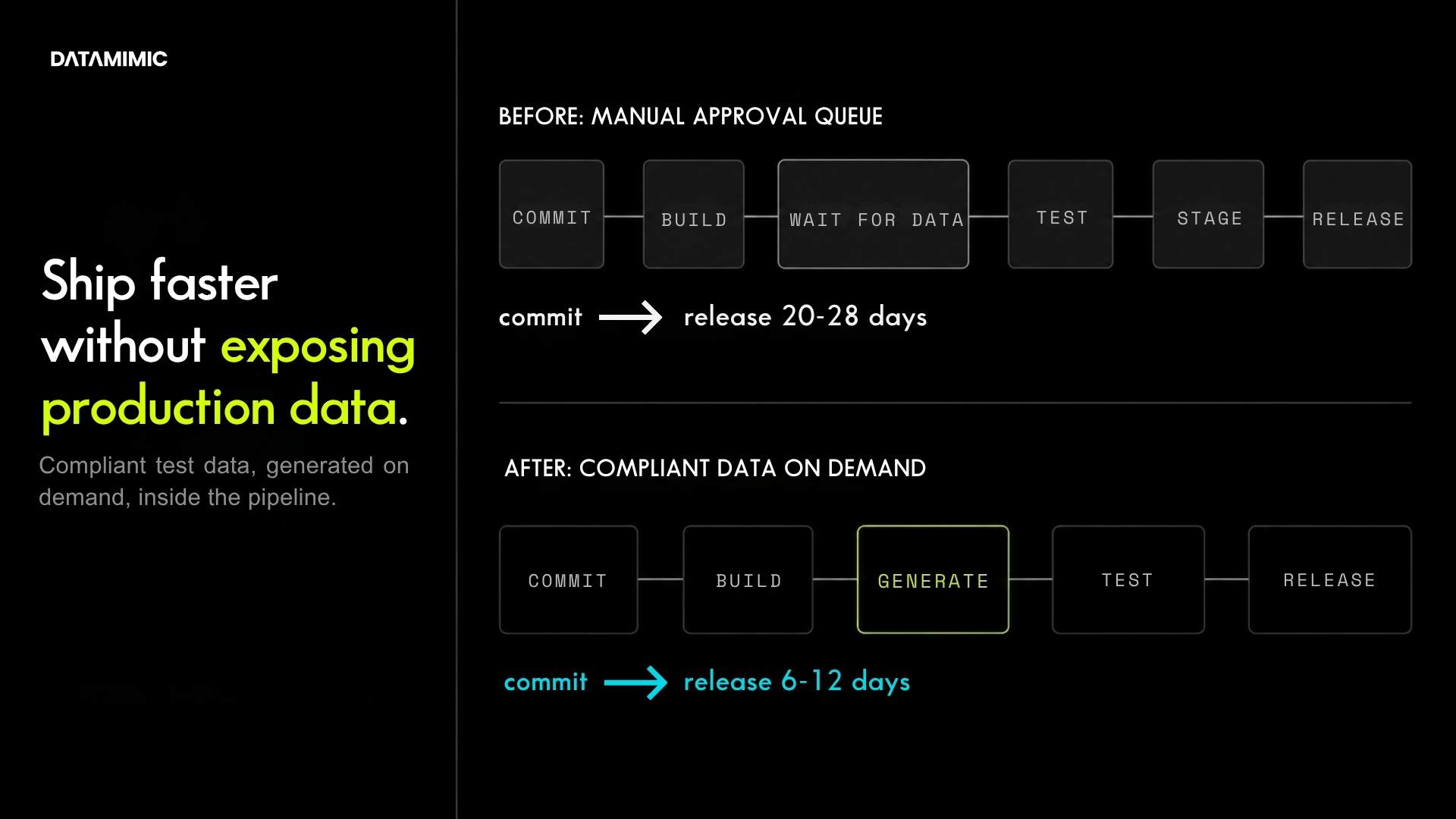
Real-Time Data Masking in Kafka Streams for Payment Systems
Real-time data masking for Kafka Streams: deterministic, replay-safe, format-preserving. Five techniques, production-grade requirements, and a runnable proof you can verify on your laptop....