Home › What Is Deterministic Test Data? And Why Regulated Teams Need It
What Is Deterministic Test Data? Why Regulated Teams Need It
For regulated engineering teams, test data is no longer just a QA input. It affects release confidence, auditability, incident investigation, and how safely teams work in non-production environments.
That pressure is only getting stronger. In the EU financial sector, the Digital Operational Resilience Act (DORA) has applied since 17 January 2025 and sets expectations around ICT risk management and operational resilience. In parallel, GDPR still requires organizations to think carefully about how personal data is protected, including in testing and development workflows.
That is where deterministic test data becomes strategically important.
It gives teams a way to create reproducible test data on demand, preserve referential integrity, and rerun the same scenario across environments without relying on stale copied datasets or fragile manual fixes.
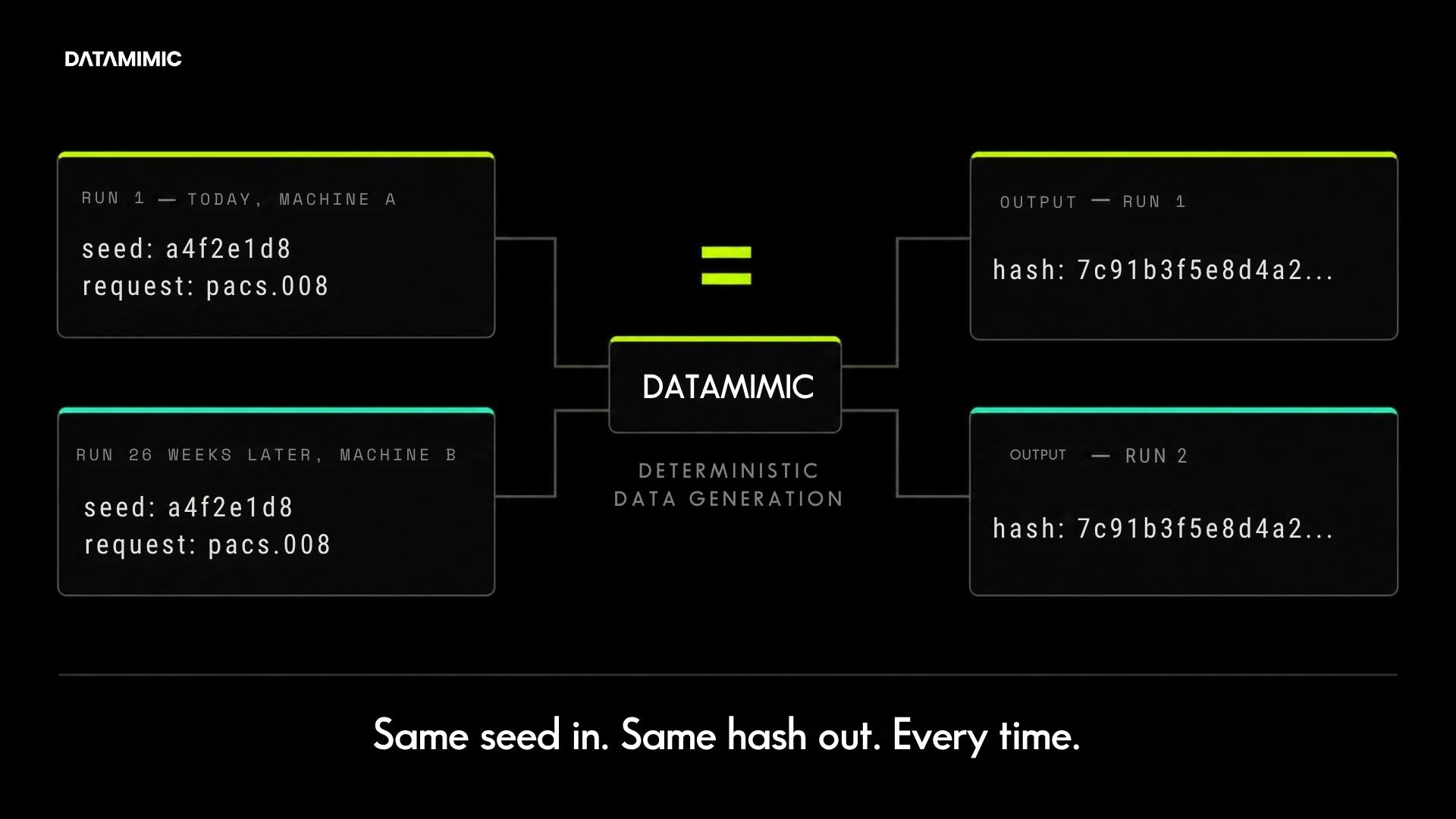
What does deterministic test data actually mean?
In practical terms, deterministic test data means the same rules, the same configuration, and the same seed or request produce the same output every time.
That sounds simple, but it changes the role test data plays in modern delivery. The goal is not just to make data look realistic once. The goal is to make it repeatable, explainable, and regenerable when teams need to rerun a defect, validate a control, or investigate a failure.
This is especially important in regulated environments, where test evidence often needs to be explained across engineering, QA, platform, security, and compliance teams.
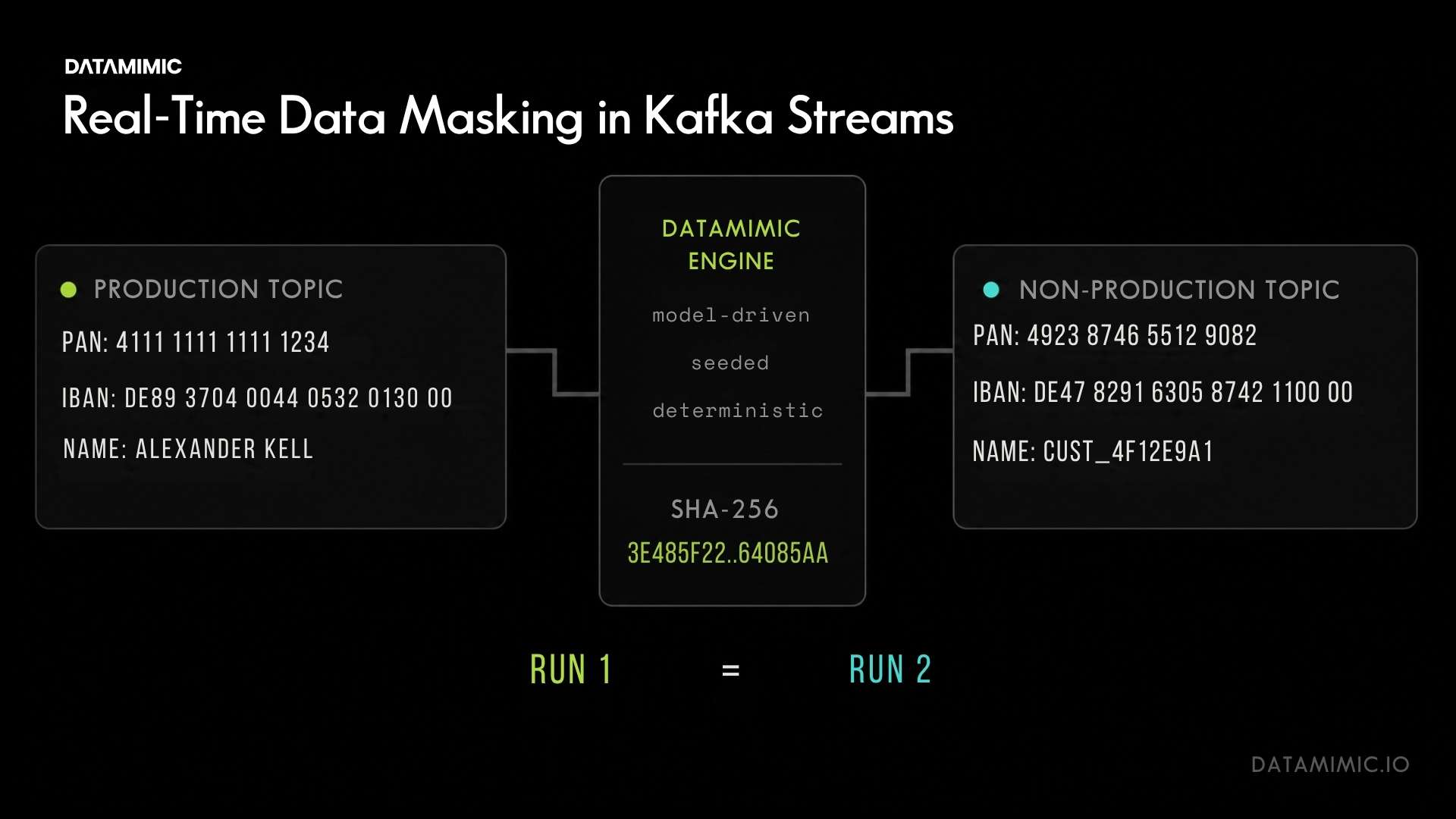
At a product level, DATAMIMIC works by separating the data model from the data targets. The DSL describes entity relationships and constraints once; the engine then generates Oracle rows, MongoDB documents, Kafka events, and JSON payloads from the same model, with identifiers that remain consistent across all targets. The same engine version, model, and seed produce byte-identical per-record output across machines and runs, which is what makes the test data audit-defensible.
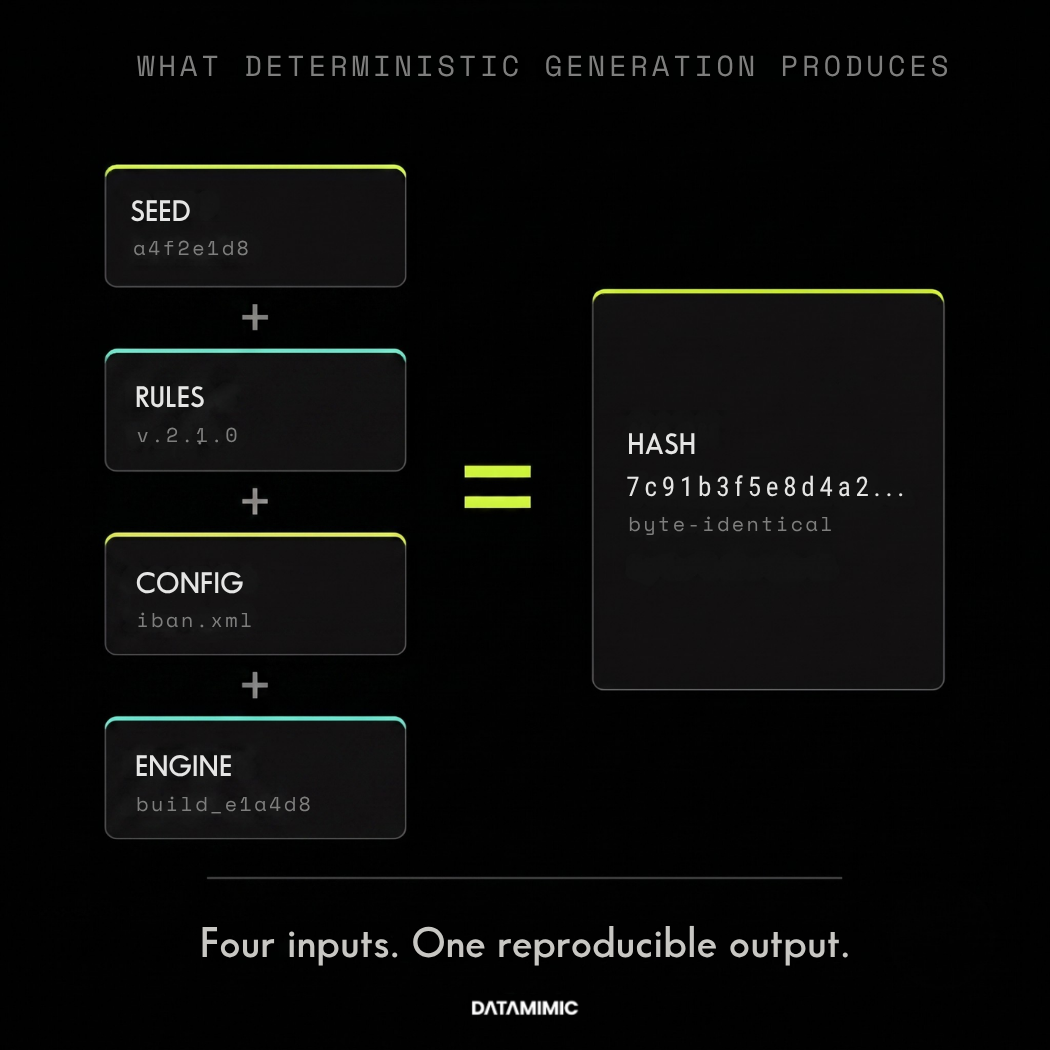
Why do regulated teams care more about reproducibility than realism?
A dataset can look realistic and still be poor test data.
That usually happens when it cannot be recreated consistently, or when the relationships inside the data no longer hold. Customer entities stop lining up with accounts. Events no longer match upstream state. Nested payloads drift away from the systems that are supposed to consume them.
For regulated teams, that is not a minor quality issue. It can create false confidence.
A workflow may appear to pass in test, while the data underneath no longer reflects the business logic the system is supposed to handle. In banking, payments, and insurance flows, that can weaken regression testing, root-cause analysis, and audit readiness.
This is why reproducible test data matters more than “production-like” test data in many regulated settings. Reproducibility lets teams rerun the same case, isolate the same defect, and explain the same result.
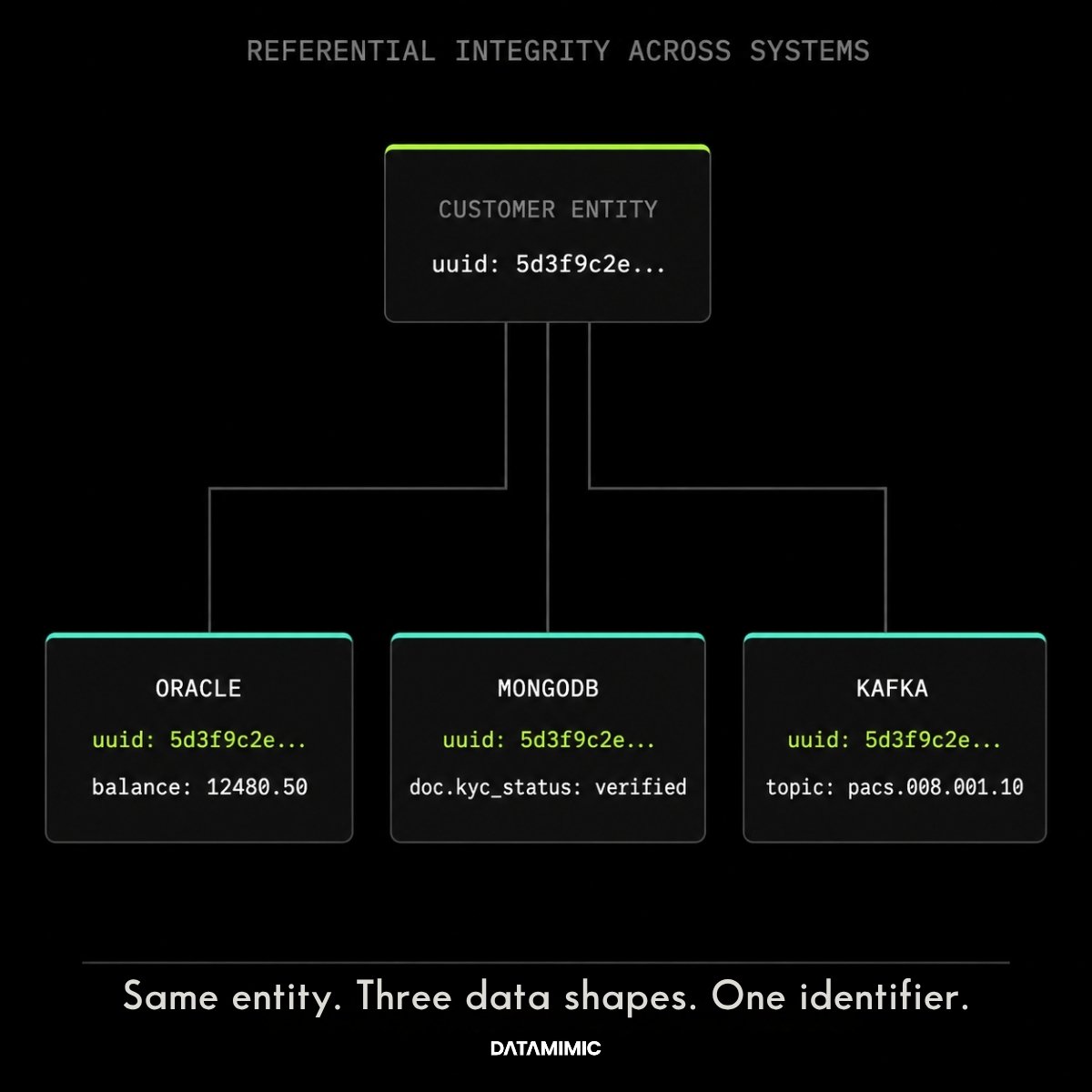
Why is referential integrity the real dividing line?
The core question is not only whether test data is private enough. It is whether the data still behaves correctly across systems.
That is where referential integrity and cross-system integrity become non-negotiable.
If your records no longer stay aligned across databases, APIs, document stores, and event streams, you are not really testing system behavior. You are testing a distorted copy of it.
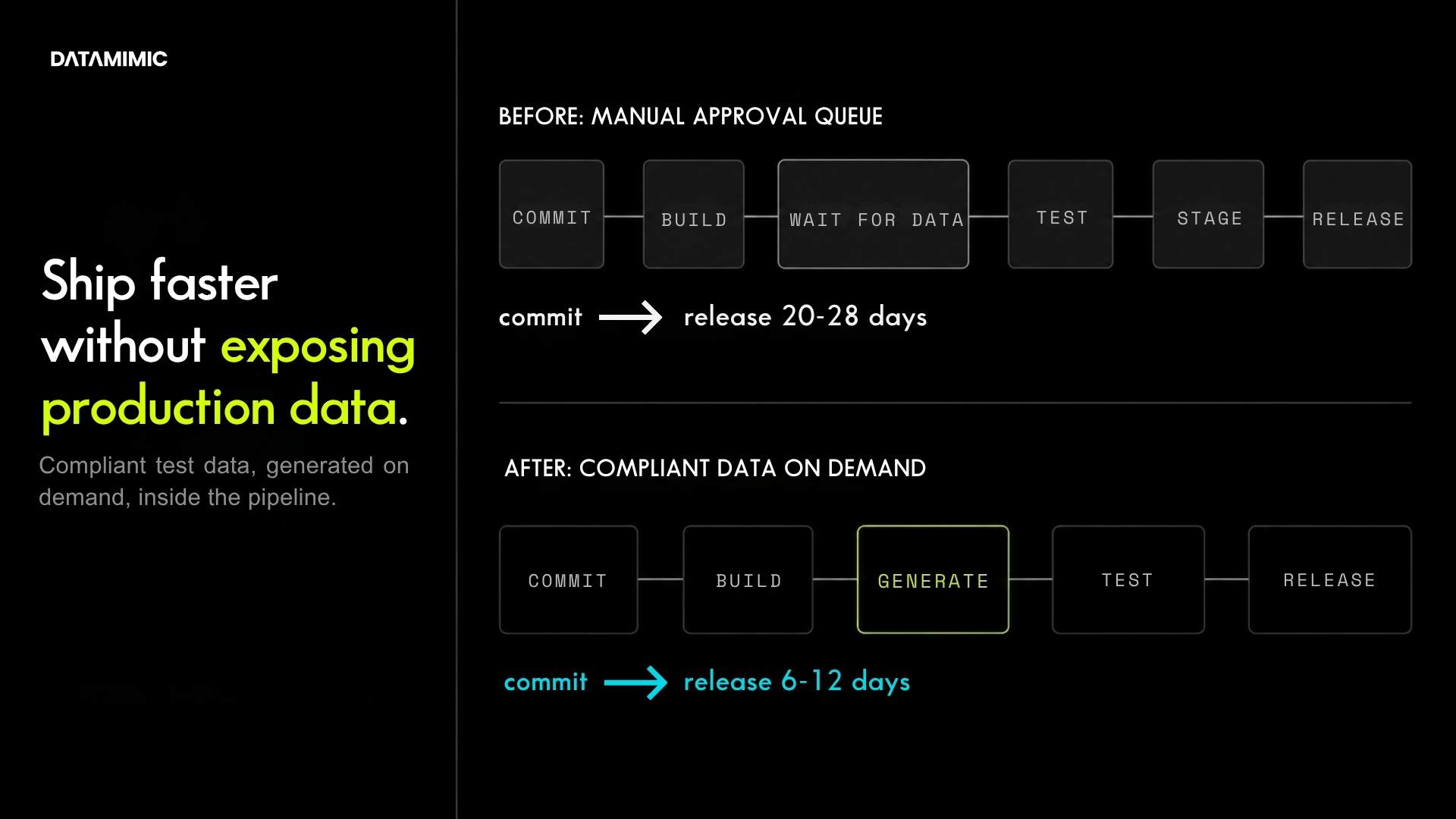
In the Tier-1 European bank case study, the same rules definition produced consistent customer, account, and transaction entities across Oracle, MongoDB, and Kafka, preserving the JSON joins that previously broke under manual patching. Where masked production snapshots had taken 20–28 days to prepare with 5–6 engineers, the model-driven approach cut preparation to 6–12 days and raised cross-team parallel execution from 0% to 90%, through Tosca DI and CI/CD integration.
For teams working with Oracle, MongoDB, and Kafka in the same workflow, that difference is huge.
Why do masked snapshots break in complex architectures?
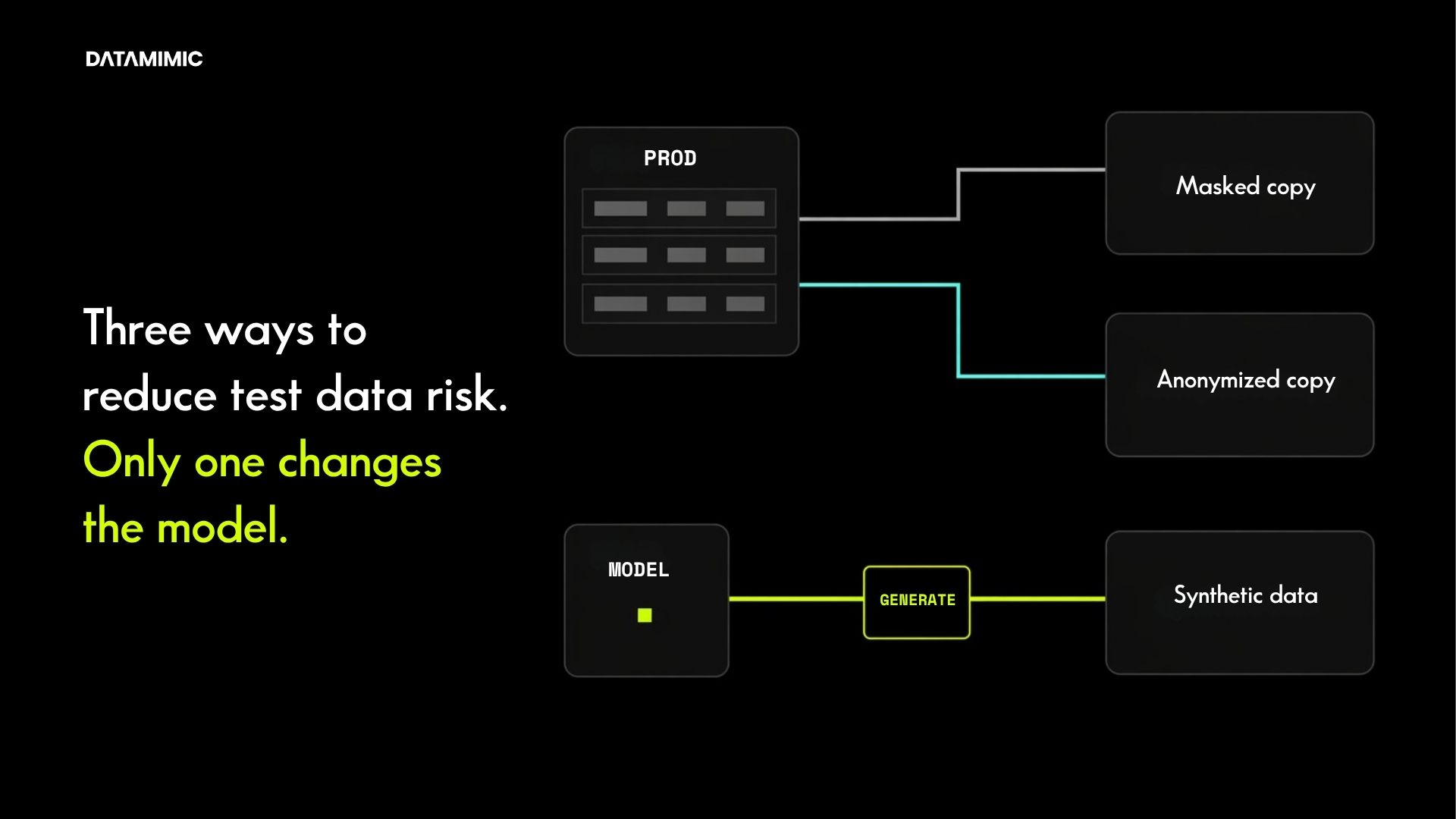
Traditional masking still has a place. For some live or transitional use cases, teams may need data masking and anonymization controls around real records.
But copied-and-masked datasets often become fragile as soon as architecture gets more complex.
Modern enterprise testing rarely stops at flat tables. It spans APIs, nested payloads, event streams, document stores, and multiple schemas evolving at the same time. That is where teams start compensating with post-processing scripts, manual patching, and repeated refresh cycles.
Regulators also make an important distinction here. The UK ICO’s guidance explains that anonymisation and pseudonymisation are not the same thing, and pseudonymised data can still remain within the scope of data protection obligations. That is one reason many teams start looking for safer, more maintainable alternatives for non-production testing.
If your lower environments still depend on transformed versions of real identities, you may reduce exposure without fully removing privacy risk or operational maintenance overhead.
That is why the right comparison on this topic is not only “masked or unmasked.” It is also synthetic data and anonymized data, and more broadly, synthetic vs masking for repeatable engineering use cases.
When does deterministic generation matter most?
Deterministic generation matters most when structure matters.
If a team needs to generate deterministic JSON or XML data for nested enterprise structures, the challenge is not just generating values. It is generating the right structure, preserving hierarchy, and keeping connected entities aligned across systems.
DATAMIMIC handles deeply nested JSON and XML structures by representing them as hierarchical models with parent-child generation order, so foreign references resolve before they are consumed. Models can also be auto-generated from existing JSON samples or from database schemas, which lets teams bootstrap a test data model from an existing system without writing the model by hand.
That makes deterministic, schema-based generation much more useful than random record creation when teams need stable contract testing, integration testing, or complex workflow validation.
What does good deterministic test data infrastructure look like?
A strong deterministic test data approach usually has six qualities:
- It is rule-driven, not dependent on one-off manual refreshes.
- It supports repeatable generation with stable logic.
- It preserves referential integrity across systems.
- It handles structured and nested formats, not just flat tables.
- It supports on-demand test data in CI/CD pipelines.
- It leaves an explainable trail of how data was generated.
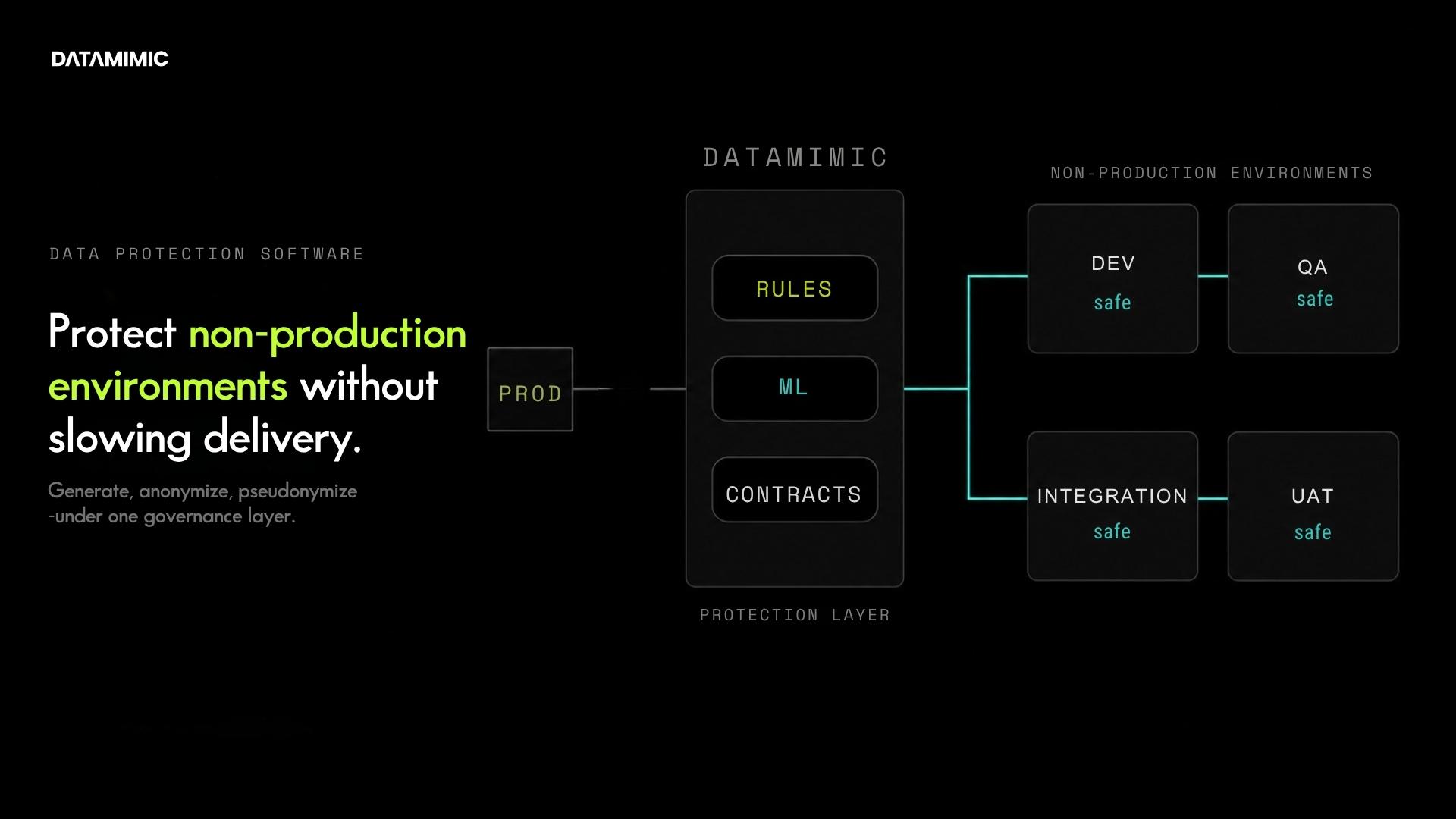
DATAMIMIC exposes a REST API plus a Python SDK; either can trigger a generation run from a CI/CD job with the model passed as code or as XML. Runtime properties (worker count, target environment, seed) can be injected per run without modifying the project files, which lets the same model serve dev, QA, integration, and UAT pipelines in parallel with isolated state.
That is the point where test data stops being a setup task and starts becoming infrastructure.

How is deterministic test data different from real-time data de-identification?
It is important to separate two closely related but different problems.
For non-production engineering, deterministic generation is often the better answer because it creates new, controlled data specifically for testing.
For live operational flows, the requirement may be different. Some teams need real-time pseudonymization and anonymization for Kafka data, streaming data, or payment data while real records continue to move through operational systems.
These are related concerns, but they should not be treated as the same use case. For example, the ACI Worldwide case study on real-time pseudonymization and anonymization of streaming payment data addresses a different operational challenge: Kafka-based payment streams, deterministic pseudonymization for consistency across 140 to 180-column entities, and audit-ready de-identification at very high throughput.
In simple terms: for live flows, the priority is protecting real data in motion. For non-production testing, the priority is generating reproducible, safe, and controllable test data that teams can rerun with confidence.
What does this look like in real regulated environments?
The strongest proof on this topic is not abstract.
DATAMIMIC’s Tier-1 European Bank case study shows a deterministic test data scenario across Oracle, MongoDB, Kafka, JSON, Tosca DI, and CI/CD. The published results describe faster preparation, fewer manual fixes, and parallel team execution after moving away from masked snapshots toward deterministic rulesets.
That is exactly the kind of environment where test data for regulated environments needs to be more than safe-looking. It needs to be reproducible.
For technical evaluators, the public DATAMIMIC documentation, GitHub repository, and PyPI package all reinforce the same positioning: model-driven, deterministic synthetic test data for CI/CD and other complex testing workflows.
Bottom line
If your team works in payments, banking, insurance, or any other tightly governed environment, the better question is not:
“Does this data look realistic enough?”
The better questions are:
- Can we recreate it?
- Can we explain it?
- Can we keep relationships intact?
- Can we regenerate it when schemas change?
- Can we use it safely in automated delivery?
That is why deterministic test data is becoming a core capability for regulated engineering teams.
If you are rethinking your broader data protection software strategy for non-production environments, deterministic generation belongs in that conversation. And if you want a direct comparison with legacy methods, read DATAMIMIC’s guide to data masking and anonymization and its deeper comparison of synthetic data and anonymized data.
You can also review the Tier-1 bank case study, explore the product documentation, or download the DATAMIMIC factsheet to evaluate what a reproducible test data workflow could look like in your environment.
FAQ
1. What is deterministic test data?
Deterministic test data is test data generated so the same rules and inputs produce the same output every time.
2. Why is reproducible test data important for regulated teams?
Because regulated teams often need to rerun scenarios, investigate defects, explain outcomes, and support control or audit processes consistently.
3. Why does referential integrity matter in test data?
Because realistic single values are not enough. Records and entities must still connect correctly across systems for tests to reflect real behavior.
4. How is deterministic test data different from masked production data?
Deterministic test data is generated from controlled logic and can be recreated consistently. Masked data starts from copied production records and often becomes harder to maintain as systems evolve.
5. Where does deterministic generation help most?
It helps most in complex environments with APIs, databases, nested JSON/XML structures, event streams, and CI/CD-driven testing.

March 12, 2026
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly