Home › Data Masking vs Anonymization vs Synthetic Data: What Actually Reduces Risk?
Data Masking vs Anonymization vs Synthetic Data: What Actually Reduces Risk?
For CTOs, QA leads, and other senior technology decision-makers, this is not a terminology question. Most already understand the broad difference between masking, anonymization, and synthetic generation. The real issue is which approach reduces risk without preserving the same provisioning delays, governance drag, and structural weaknesses that made production-derived test data a problem in the first place
That is why data masking vs anonymization is no longer the full decision. It is only the first layer. The more strategic question is when synthetic data vs data masking becomes the more relevant comparison, because that is usually the point where the organization stops asking how to protect copied data and starts asking whether it should still be copying it at all.
In practice, the three approaches solve different classes of problem. Production data masking is a control around copied data. Anonymization is a stronger privacy objective applied to copied data. Synthetic data is a way to reduce dependence on copied data in the first place. For regulated teams, that difference matters because the real risk is rarely just a field-level exposure problem. It is the combined effect of exposure, brittle refresh cycles, limited scenario coverage, repeated approvals, and non-production data models that do not scale.
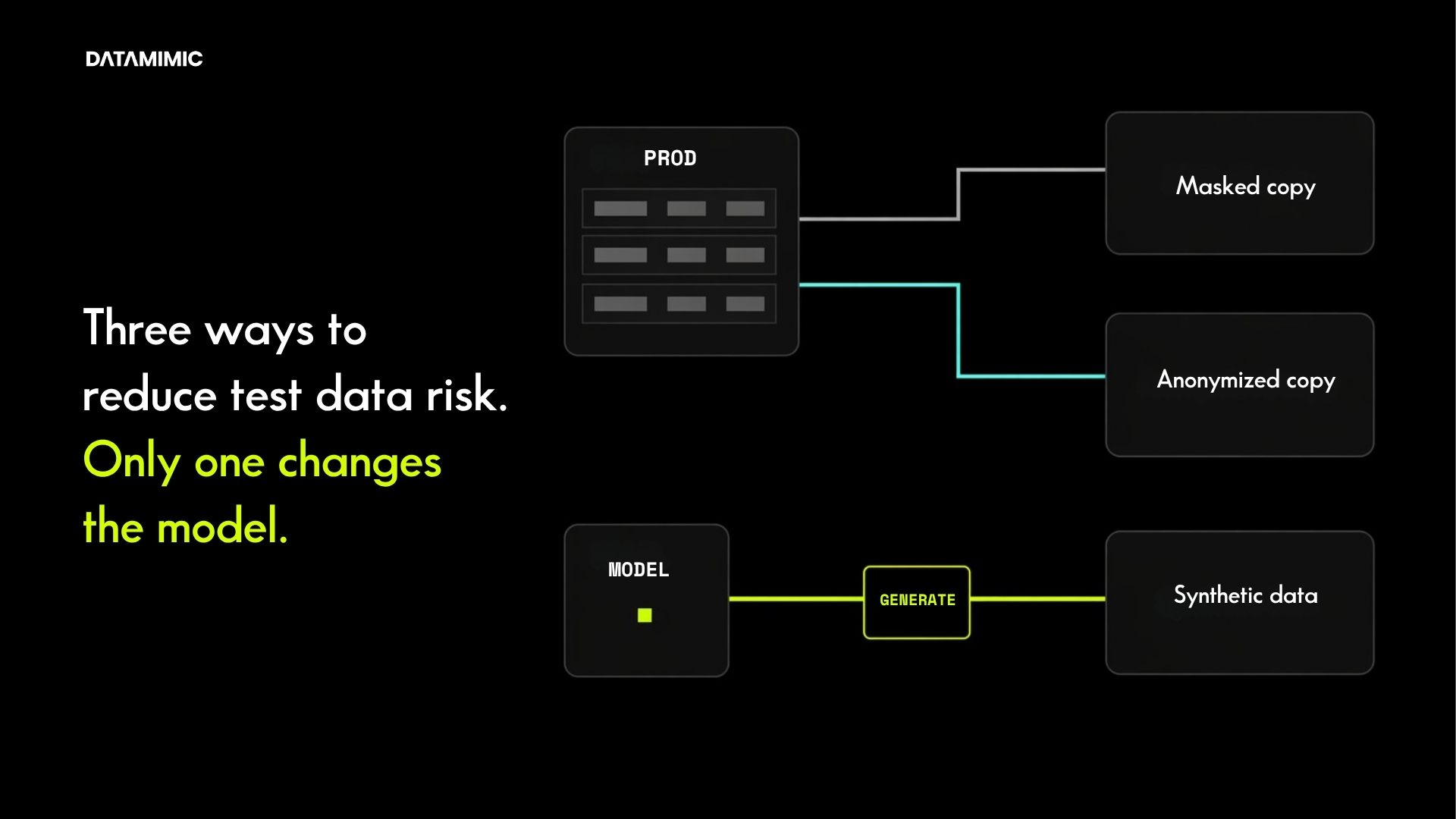
Why is data masking vs anonymization no longer the full decision?
Most comparison articles stop too early. They focus on which method hides sensitive values more effectively. That is useful, but too narrow for a senior buyer.
The more important question is what kind of test data privacy operating model each method creates.
Masking is often the fastest way to reduce obvious exposure inside an existing workflow. But it leaves the workflow fundamentally intact. Teams are still provisioning production-derived data, still inheriting its history and gaps, and still depending on controls around copied assets.
Anonymization raises the privacy bar, but it still works inside the same basic model. The organization is still starting from real records and then trying to transform them enough to make their reuse acceptable.
Synthetic data changes the frame. It asks whether useful, realistic data can be generated without keeping the organization tied to production-derived copies as the default non-production supply model. That is why the more focused two-way comparison between synthetic data vs anonymized data is valuable, but it does not replace this page. This page exists to answer the broader question of what actually reduces risk when masking is still on the table.
For senior teams, that broader comparison matters because privacy method and delivery model are not separate decisions. In real environments, they are linked.

Where does production data masking still fit?
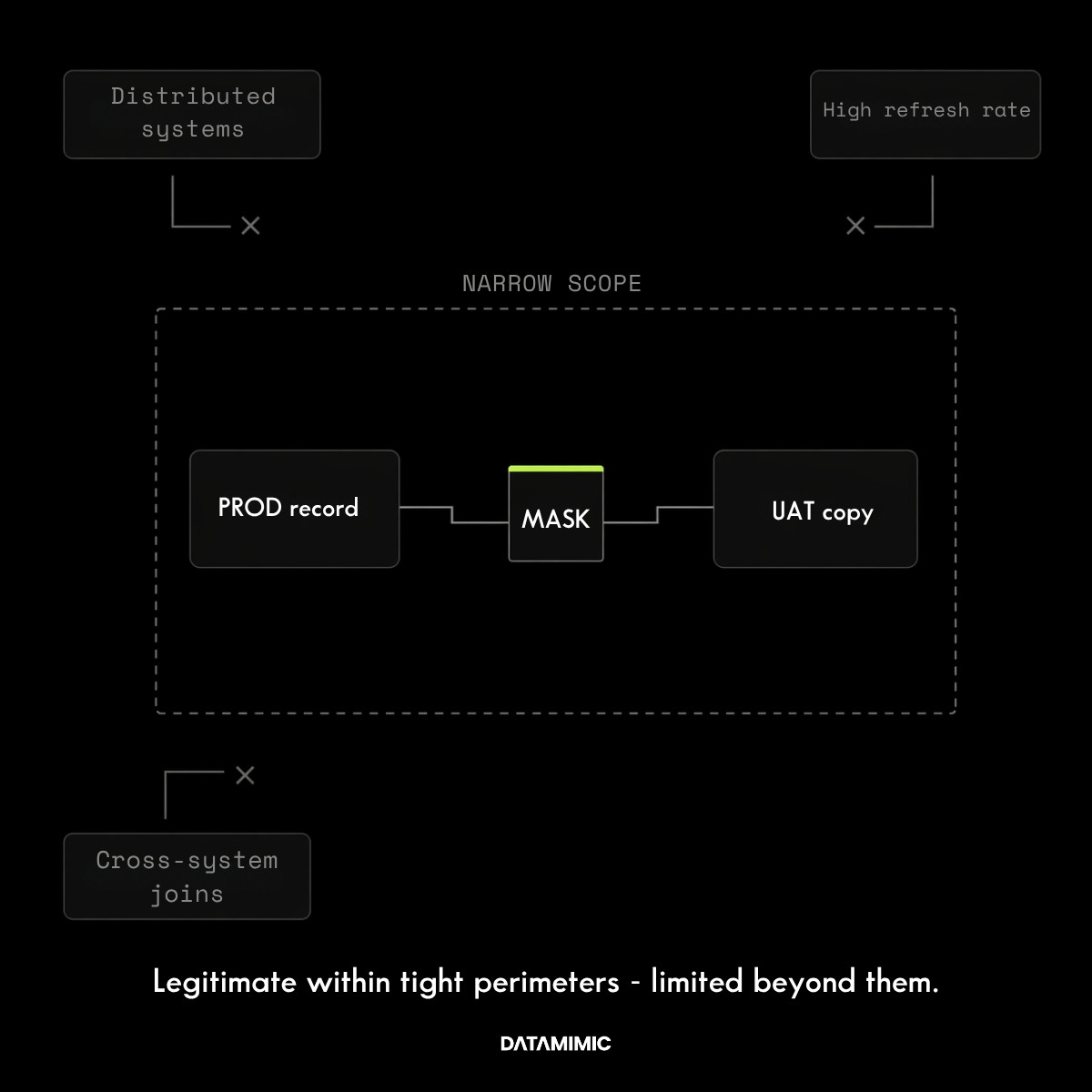
Masking still has a legitimate place.
If the use case is narrow, the environment is tightly controlled, and the main requirement is to obscure a subset of sensitive values inside an existing process, masking can be a rational choice. It is familiar, relatively easy to explain internally, and often faster to implement than a more fundamental redesign of test data operations.
That makes it useful for constrained UAT flows, isolated systems, or transitional environments where the organization is not yet ready to rethink how non-production data is provisioned.
But the limits of masking usually appear once the environment becomes more distributed or the testing need becomes more demanding.
Masked data is still production-derived. It still reflects what happened rather than what teams now need to test. It can protect values while leaving the same provisioning friction, historical blind spots, and workflow bottlenecks untouched. If the underlying process is slow, brittle, or hard to scale, masking often reduces exposure without reducing the operational cost of the copied-data model itself.
This is why teams eventually start looking for a masked data alternative. The issue is often no longer whether masking works at the field level. It is whether it still works at the operating-model level.
Why does anonymization improve privacy but not delivery?
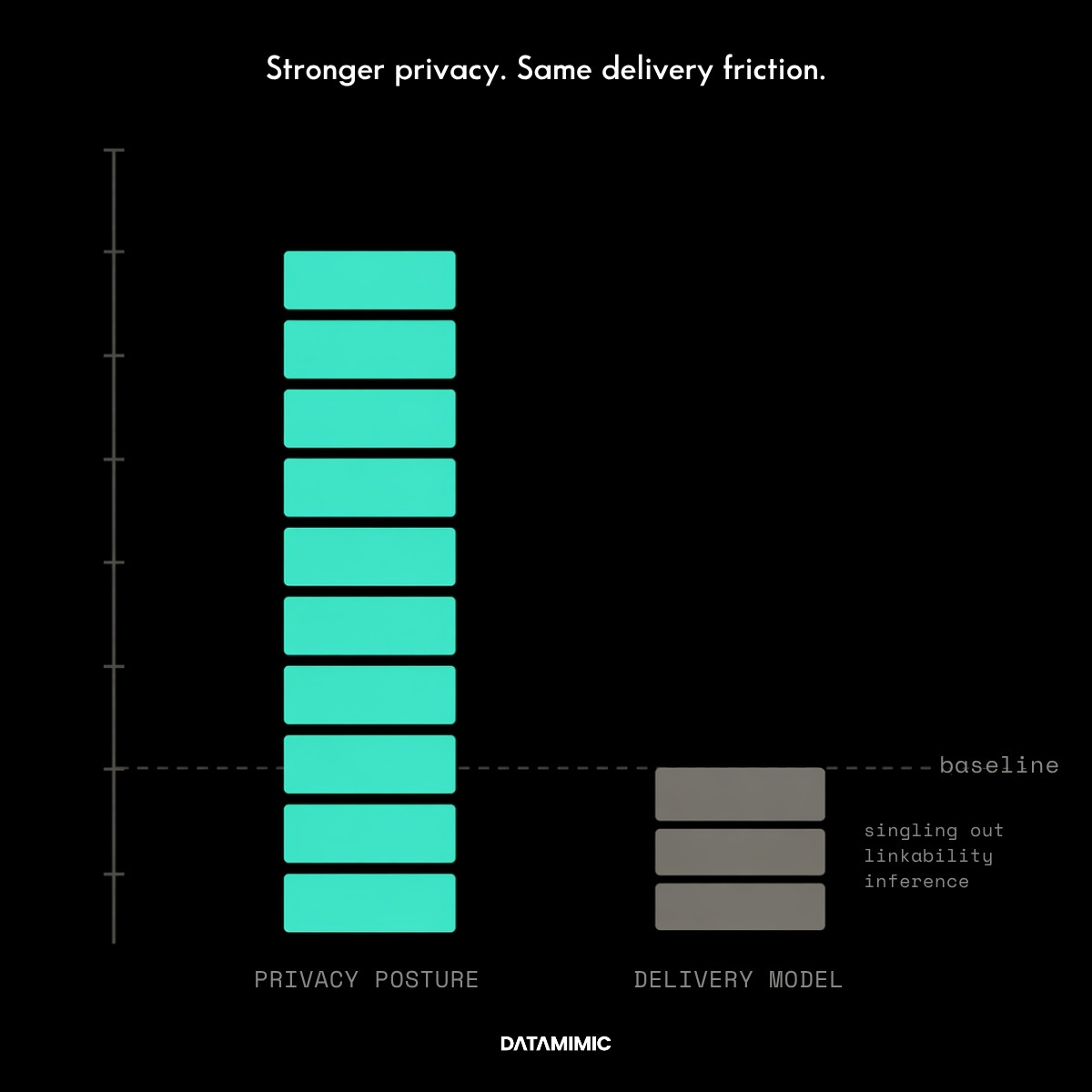
Compared with masking, anonymization is more demanding. It is not just about replacing visible identifiers. It is about whether individuals can still be singled out, linked, or inferred from the remaining dataset in context.
That is why re-identification risk matters so much here. The UK ICO’s guidance on effective anonymisation makes the point clearly: reducing risk is not just about removing direct identifiers, but about whether singling out and linkage remain possible in practice. The same logic appears in the EU opinion on anonymisation techniques, which evaluates anonymisation against risks such as singling out, linkability, and inference.
For advanced buyers, that is the correct lens. It reflects how privacy risk behaves in rich, real environments rather than in simplified examples.
Still, anonymization has an important limit: it is usually a stronger answer inside a production-derived model, not a replacement for that model.
Even well-anonymized data is still constrained by the source it came from. It tends to preserve the structure, coverage limits, and provisioning mechanics of the copied-data workflow. So while anonymization may be the stronger answer to the question “how do we reduce identifiability in a copied dataset?”, it is often a weaker answer to the question “how do we create safer, faster, and more flexible non-production data operations?”
That is where many organizations misread the trade-off. They improve the privacy layer while leaving the delivery layer largely intact.
How does synthetic data change the operating model?
Synthetic data matters because it does not begin from the assumption that production-derived copies must remain the default.
That makes it a different class of decision.
When the goal is no longer just to harden copied data, but to reduce dependence on copied data operationally, synthetic generation becomes much more relevant. This is especially true in environments where testing requires broader safe access, more frequent provisioning, deeper scenario coverage, or more repeatable behavior across systems and pipelines.
That does not mean synthetic data should be treated as automatically risk-free. The ICO glossary explicitly notes that synthetic data may or may not be anonymous, depending on how it is produced and what it preserves. Senior buyers should be skeptical of simplistic claims here.
The right question is whether a specific synthetic approach is strong enough to support serious engineering work while improving the privacy model at the same time.
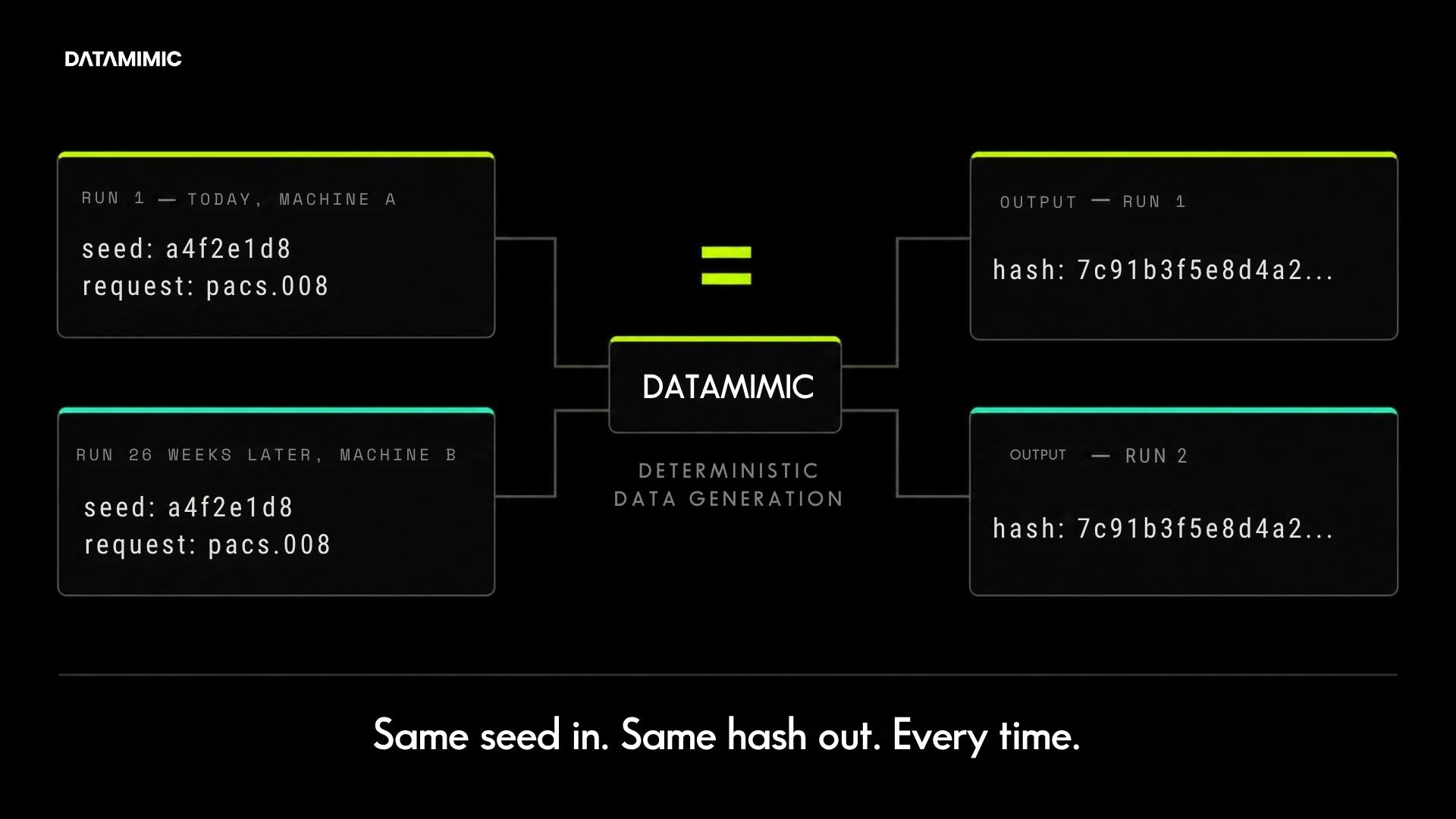
That is why the evaluation should not stop at “does the data look realistic?” It should move toward questions like: can the approach support complex structures, engineered scenarios, explainable generation, and broader safe access without keeping the same copied-data dependencies underneath? When the real problem now includes repeatability, cross-system consistency, and non-production reliability, the more useful next step is often to evaluate deterministic test data rather than keeping the conversation only at the level of privacy technique.
What should senior buyers evaluate before choosing?
First, ask whether the risk you are trying to reduce is mainly field-level exposure or broader dependence on production-derived data. If it is mostly the former, masking or anonymization may still be enough. If it is also the latter, synthetic data deserves a more serious evaluation.
Second, ask whether the method improves only privacy posture or also delivery performance. A solution that lowers exposure but still leaves teams waiting on refreshes, approvals, or brittle joins may not reduce risk as much as it appears to.
Third, test how the method behaves in the real environment, not in a flat-table demo. Complex systems rarely fail on simple value substitution. They fail on relationships, nested structures, event payloads, and cross-system consistency. That is why senior teams evaluate not only privacy controls but also provisioning logic, workflow fit, and the ability to support realistic scenarios under change.
Fourth, ask whether the method scales with organizational use. Some approaches look acceptable in a tightly controlled pilot and begin to break once more teams, more environments, and more release pressure enter the picture.
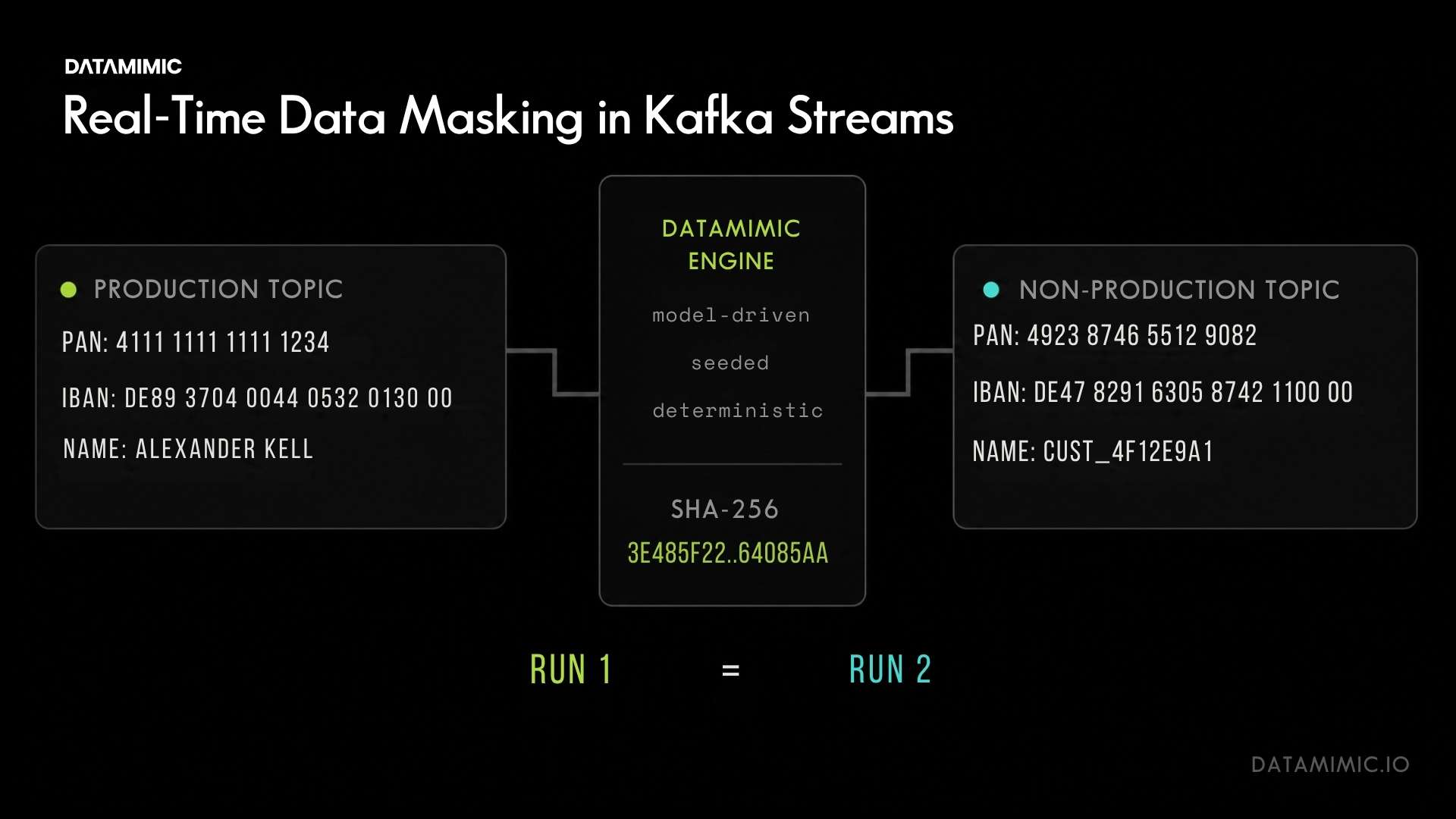
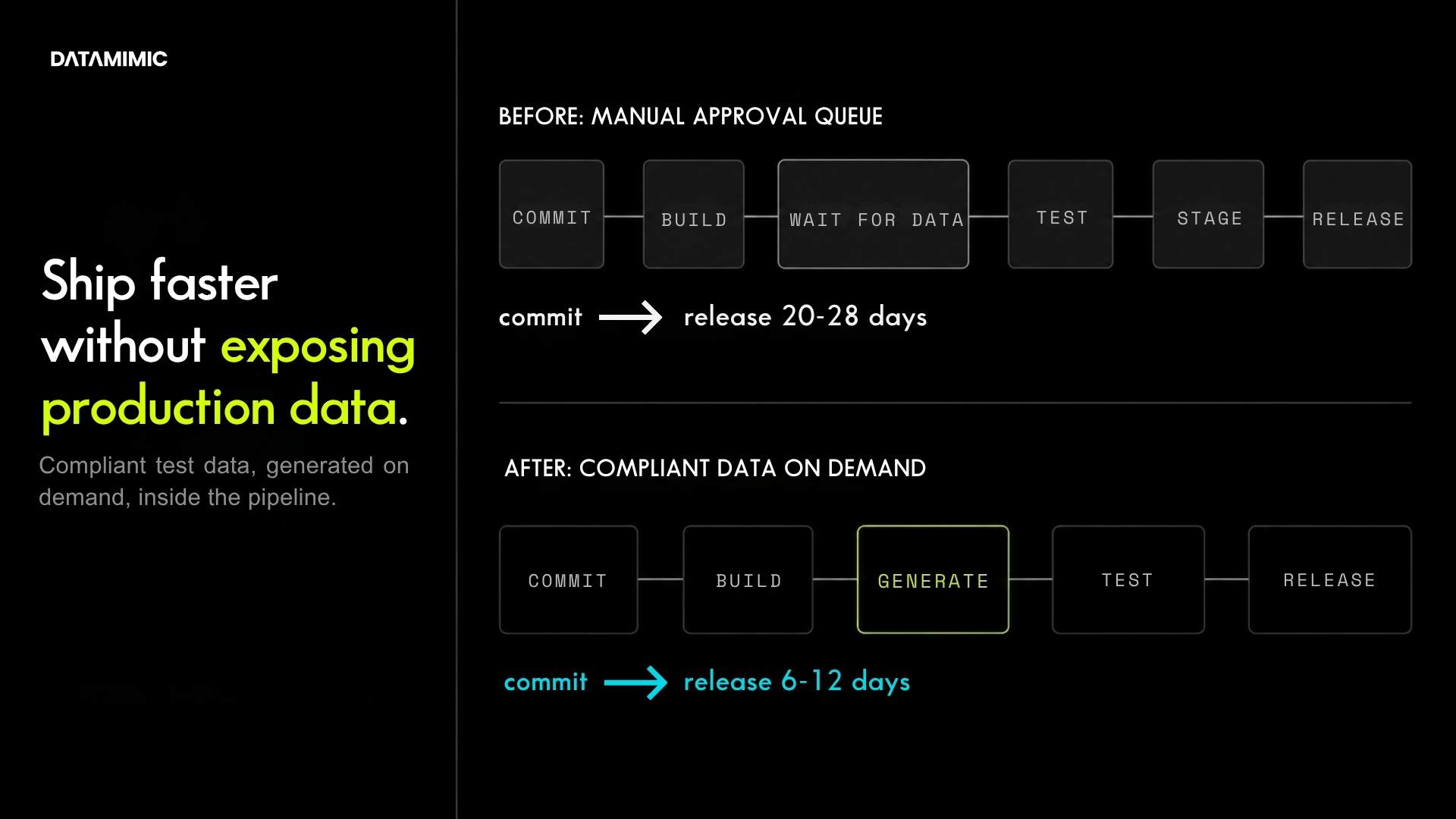
This is where proof matters. In DATAMIMIC’s Tier-1 European bank case study, masked snapshots took 20-28 days to prepare, involved 5-6 engineers, and often broke JSON joins across Oracle, MongoDB, and Kafka. The team moved to a model-driven approach where one rules definition produced aligned entities across all three systems with consistent identifiers, replacing the snapshot-and-mask cycle with on-demand generation in CI/CD.
If your organization is already seeing the same pattern—copy-dependent refreshes, broken relationships, and slow test-data turnaround—the strategic question is no longer only about privacy technique. It is about architecture.

Which approach actually reduces your risk?
For advanced buyers, this blog should not end with “it depends.”
The more useful conclusion is this: the right choice depends on what kind of risk you are actually trying to remove.
If you need a local protection layer around copied data, masking may still do the job.
If you need a stronger privacy outcome while staying inside a production-derived model, anonymization may be the better step.
But if your real problem now includes data masking and anonymization overhead, repeated governance friction, limited scenario coverage, and the cost of staying tied to copied workflows, synthetic data is usually the stronger long-term direction.
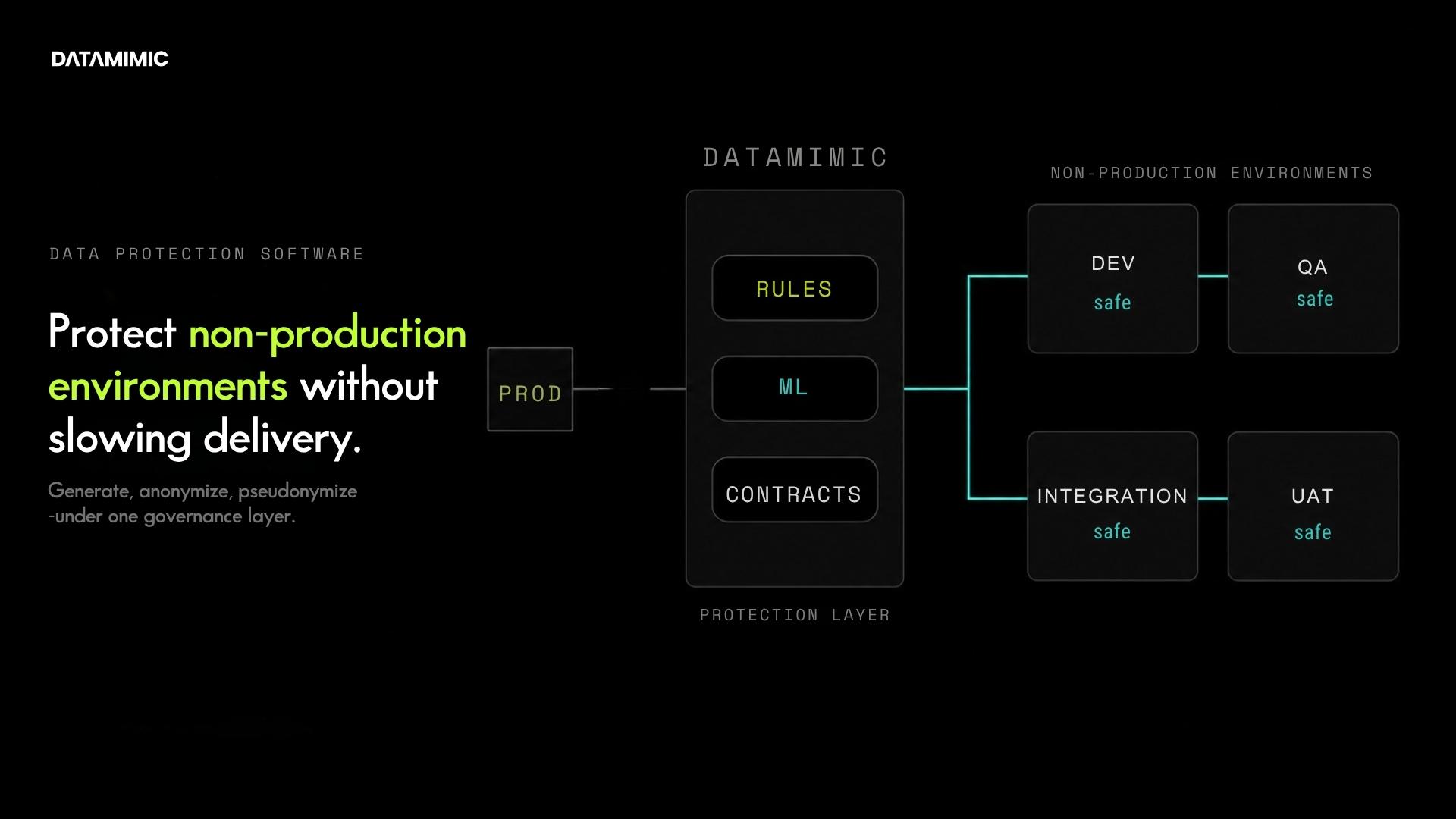
If you are evaluating that shift from a broader solution and governance perspective, DATAMIMIC’s view of data protection software for test data is the next practical step.

March 19, 2026
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly