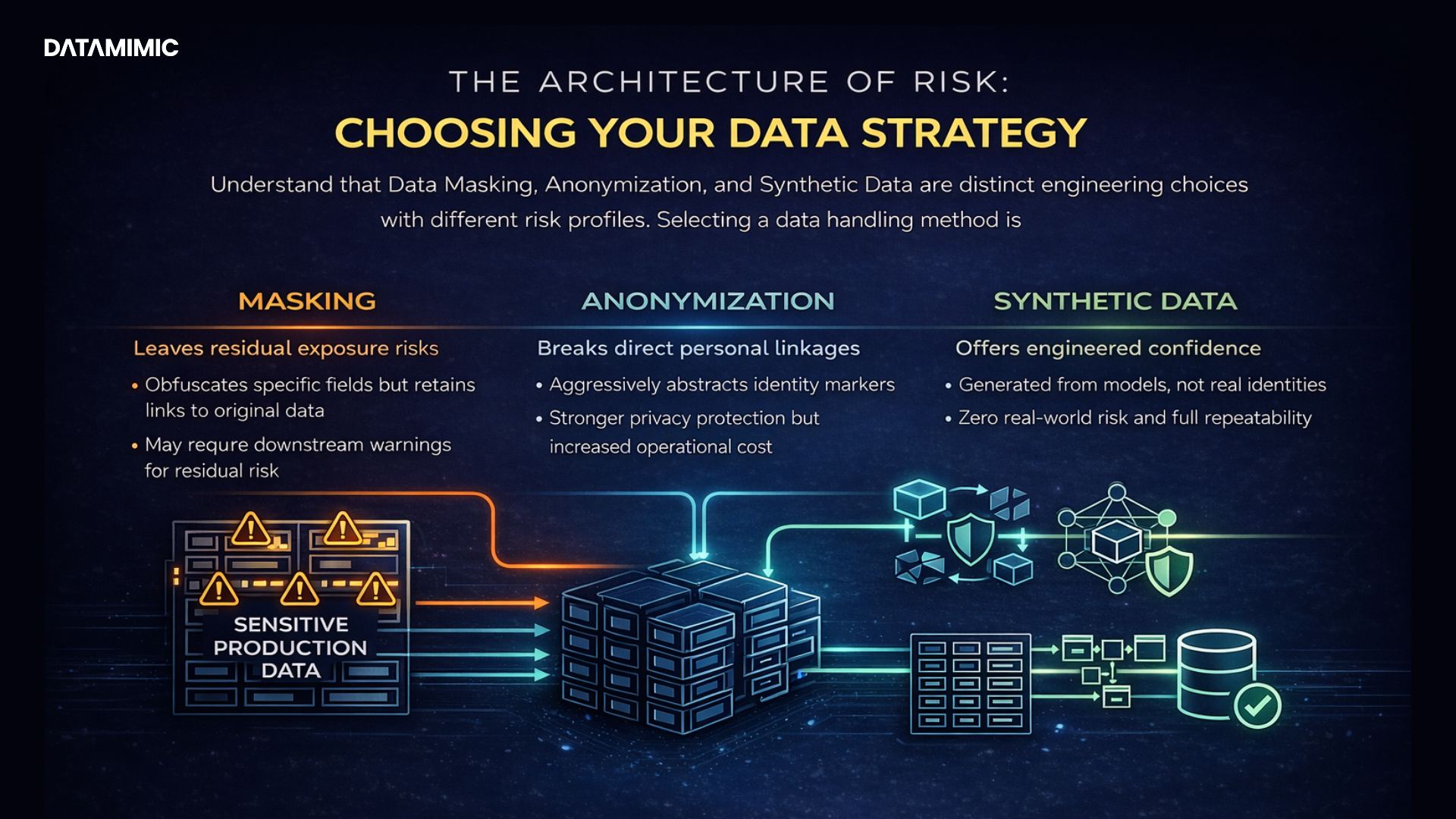
Home › What Is Deterministic Test Data? And Why Regulated Teams Need It
What Is Deterministic Test Data? And Why Regulated Teams Need It
For regulated teams, test data is no longer just a QA input. It is part of your delivery risk, your audit story, and in many cases, your broader data-governance posture.
That matters more than ever. The EU’s Digital Operational Resilience Act, or DORA, has applied since 17 January 2025 and explicitly covers ICT risk management and digital operational resilience testing for financial entities. IBM’s 2025 Cost of a Data Breach Report puts the global average cost of a breach at USD 4.44 million. And the 2025 GDPR Enforcement Tracker report recorded 2,245 fines totaling about EUR 5.65 billion by 1 March 2025. On top of that, testing itself is changing fast: PractiTest’s 2026 State of Testing reports 76.8% adoption of AI in testing, while the World Quality Report 2025–26 says 43% of organizations are experimenting with Gen AI in QA, but only 15% have scaled it enterprise-wide. For regulated engineering teams, that combination creates a clear challenge: move faster, automate more, and still keep control over what happens in non-production environments.
That is exactly why deterministic test data matters.
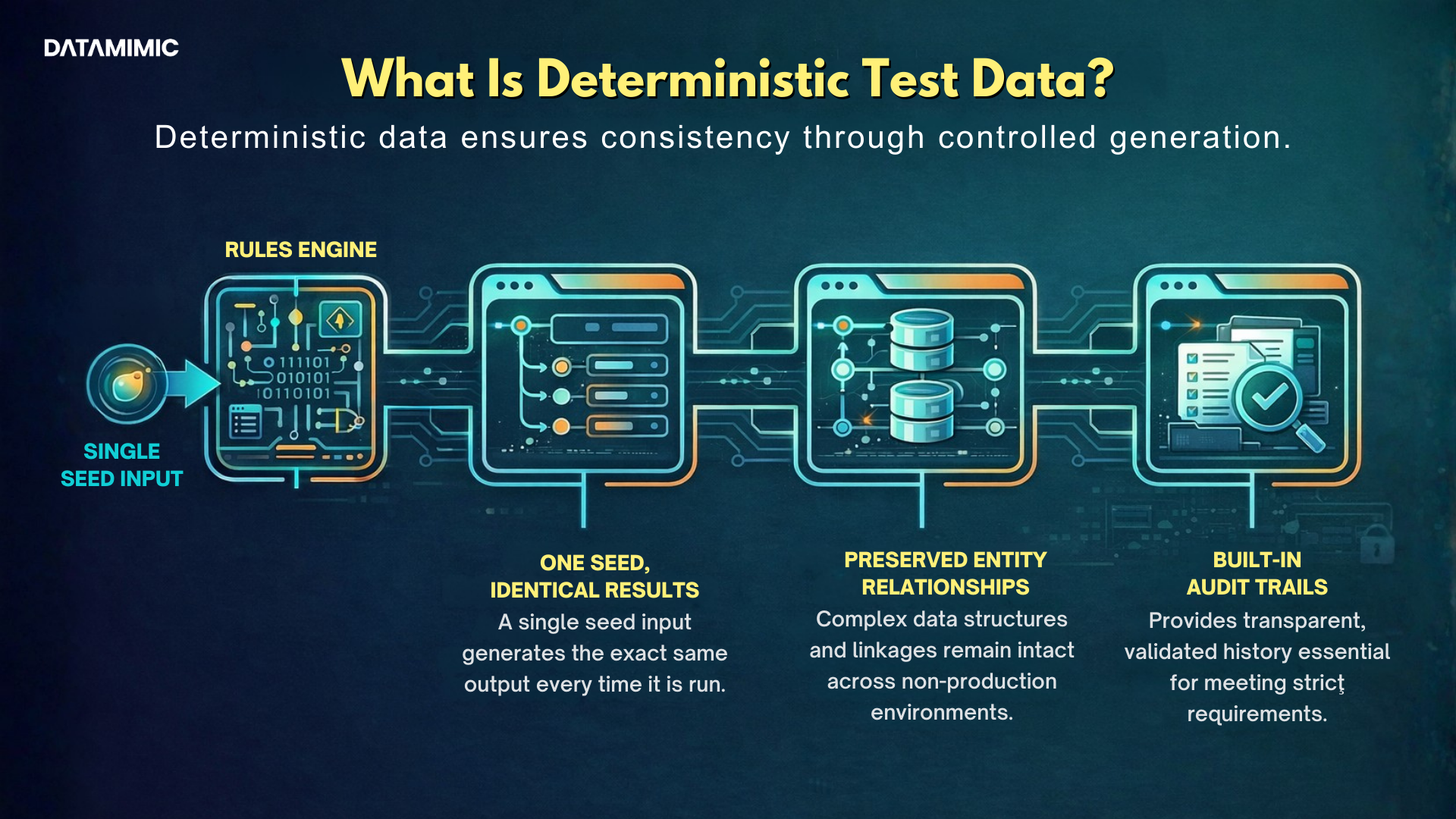
What Is Deterministic Test Data?
n practical terms, deterministic test data means the same rules, the same configuration, and the same seed produce the same output every time.
That sounds simple, but it changes the role test data plays inside a regulated delivery process. Deterministic generation is not about making data look plausible once. It is about making data repeatable on demand, across environments, machines, and CI/CD runs.
That is the difference between a dataset you can trust and a dataset you hope is “close enough.”
At DATAMIMIC, we approach deterministic test data as reproducible, rules-driven generation. That allows teams to create consistent, explainable datasets across Oracle, MongoDB, Kafka, and complex JSON payloads without relying on fragile one-off refreshes.
For regulated teams, that makes reproducible test data far more valuable than merely realistic-looking test data.
Realism helps a demo.
Reproducibility helps an investigation.
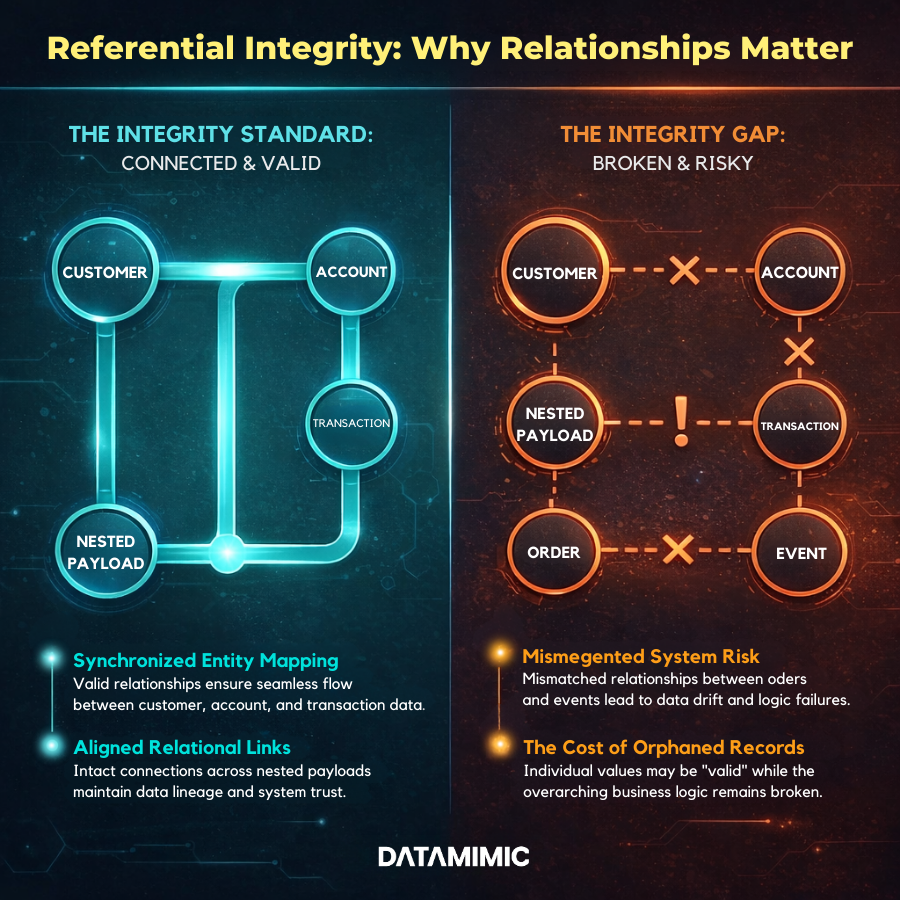
Why Regulated Teams Need Reproducible Test Data?
A dataset can be anonymized and still be bad test data.
That usually happens when the relationships inside the data no longer hold. Customer entities no longer match accounts. Orders do not line up with transactions. Event payloads no longer reflect upstream data structures. Nested objects in JSON break because one branch changed but the connected entities did not.
That is why referential integrity is non-negotiable.
In complex systems, valid-looking values are not enough. The relationships between entities also need to make sense. Otherwise, teams are not really testing end-to-end behavior. They are testing a distorted version of it.
At DATAMIMIC, we approach deterministic test data as reproducible, rules-driven generation. That allows teams to create consistent, explainable datasets across Oracle, MongoDB, Kafka, and complex JSON payloads without relying on fragile one-off refreshes.
For regulated teams, broken referential integrity is more than a technical nuisance.
It can produce false confidence.
A workflow may appear to pass, while the actual production logic it is supposed to represent has already been weakened by inconsistent relationships in the test data. That is especially risky in payment processing, claims handling, KYC, fraud controls, healthcare workflows, and other environments where system behavior depends on multiple linked records staying aligned.
That is why strong deterministic test data strategy should not only generate values. It should preserve the relationships that make those values meaningful.
Where Deterministic JSON Test Data Beats Masked Snapshots
Modern enterprise systems do not live only in tables anymore.
They live in APIs, Kafka streams, event payloads, document stores, nested JSON, XML, and cross-system integrations where the shape of the data matters just as much as the values inside it.
That is where deterministic JSON test data becomes especially important.
Traditional masking tends to perform best in relatively stable, tabular structures. But once a flow spans Oracle schemas, MongoDB collections, Kafka topics, and nested JSON payloads, teams often end up compensating with brittle joins, post-processing scripts, or manual fixes.
That is not just inefficient. It is hard to scale and even harder to audit.
DATAMIMIC’s public Tier-1 European Bank case study captures this well. According to the case study, masked snapshots previously took 20–28 days to prepare, involved 5–6 engineers, and often broke JSON joins across Oracle, MongoDB, and Kafka. The same case study says the shift to deterministic rulesets enabled zero-touch automation in Tosca DI and CI/CD, with measurable improvements in delivery speed and independence from manual refresh cycles.
That is the practical difference between “data that exists” and deterministic JSON test data.
A deterministic approach allows teams to regenerate structured payloads in a controlled way, preserve consistency across systems, and test edge cases without inheriting live-production risk.
For regulated teams, this matters because modern architecture is often where auditability gets hardest. The more systems and formats involved, the more valuable controlled, repeatable generation becomes.
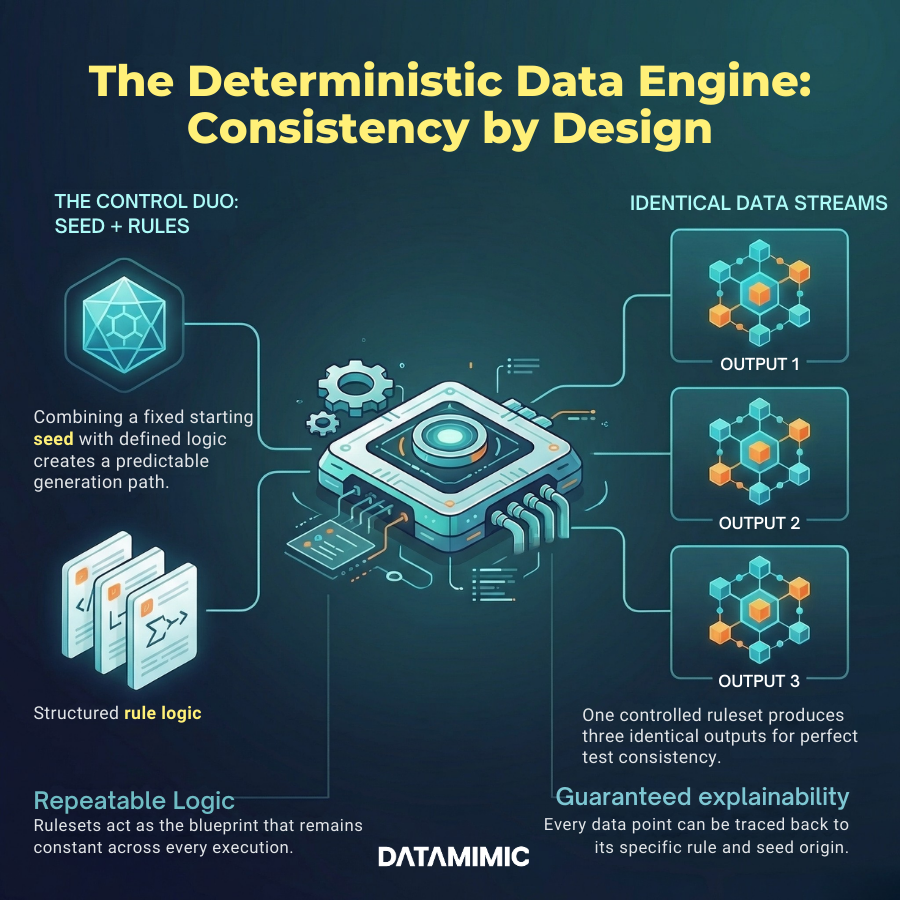
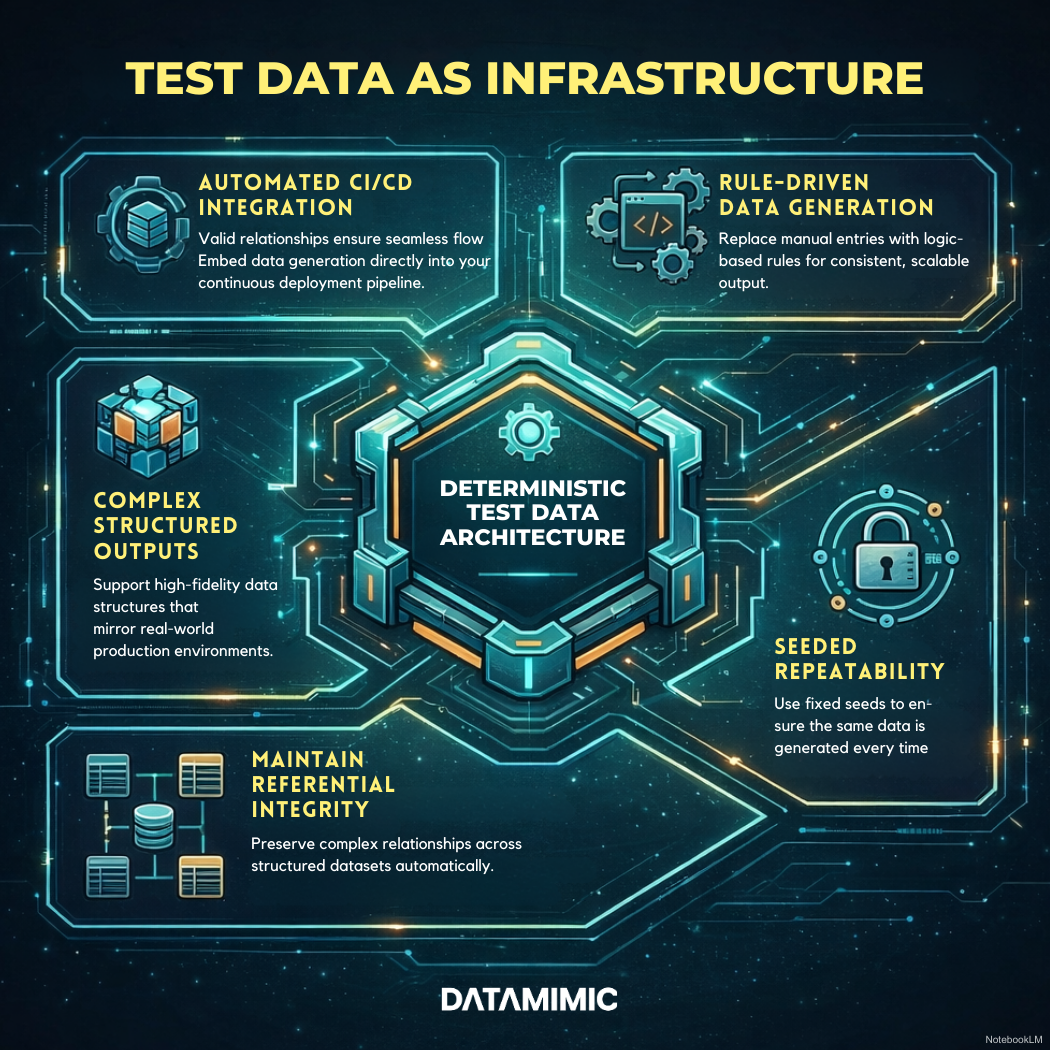
What Good Deterministic Test Data Infrastructure Looks Like
A mature deterministic test data approach usually includes five core capabilities.
First, it is rule-driven rather than dependent on one-off manual refreshes.
Second, it supports seeded generation so outputs are repeatable.
Third, it preserves referential integrity across systems, documents, messages, and APIs.
Fourth, it keeps rule history so teams can explain what changed and when.
Fifth, it fits into CI/CD instead of sitting outside delivery workflows.
This is the point where test data stops being a setup task and starts becoming test data infrastructure.
DATAMIMIC’s public materials and case studies align closely with that model. Its official product positioning focuses on model-based generation and complex, interconnected data. Its ACI Worldwide case study describes anonymizing millions of streaming payment records per hour in Kafka, with 140–180 columns per entity, while maintaining real-time processing and audit transparency. Its banking case study shows deterministic generation across Oracle, MongoDB, and Kafka tied directly into delivery pipelines.
None of that means a tool can guarantee compliance outcomes on its own.
It does mean the right architecture can reduce risk, improve auditability, and make non-production data easier to explain, rerun, and govern.
The Bottom Line for Regulated Engineering Teams
A lot of teams still judge test data by one standard: Does it look realistic enough?
For regulated environments, that is not a strong enough standard.
The better questions are:
- Can this data be explained?
- Can it be recreated?
- Can it preserve business relationships?
- Can it support testing across complex systems?
- Can compliance, QA, and platform teams rely on the same logic?
That is why deterministic test data is becoming more important, not less, even as AI use in testing grows. PractiTest’s 2026 report and the World Quality Report 2025–26 both suggest the same broader lesson: adoption is moving quickly, but scaled, trustworthy execution still lags. In that environment, repeatability and control become even more valuable.
If your team needs to rerun the exact same scenario, preserve referential integrity, and create reproducible test data across modern systems, then deterministic generation is not a nice-to-have.
It is part of building a test process that stands up under delivery pressure and audit scrutiny.
See How DATAMIMIC Works
Want to see how DATAMIMIC helps teams build deterministic test data workflows with repeatability, rule history, and strong referential integrity across complex systems?
Book a free DATAMIMIC demo to see how model-driven generation works in practice for regulated environments.
FAQ
1. What is deterministic test data?
Deterministic test data is test data generated in a repeatable way so that the same rules, inputs, and seed create the same output each time.
2. Why is reproducible test data important for regulated teams?
Reproducible test data helps teams rerun scenarios, investigate failures, support audits, and keep testing consistent across environments and pipelines.
3. Why does referential integrity matter in test data?
Referential integrity ensures that records and relationships remain valid across systems, which is essential for realistic and reliable testing.
4. What is deterministic JSON test data?
Deterministic JSON test data is repeatable structured test data used for nested JSON payloads, APIs, events, and other complex workflows.
5. How is deterministic test data different from masked production data?
Deterministic test data is generated from controlled logic and can be recreated consistently. Masked production data is often harder to maintain, explain, and reproduce over time.

Alexander Kell
March 12, 2026
Contact Us Now
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly