Home › Synthetic Data vs Anonymized Data: The Real Difference Is Dependency
Synthetic Data vs Anonymized Data: The Real Difference Is Dependency
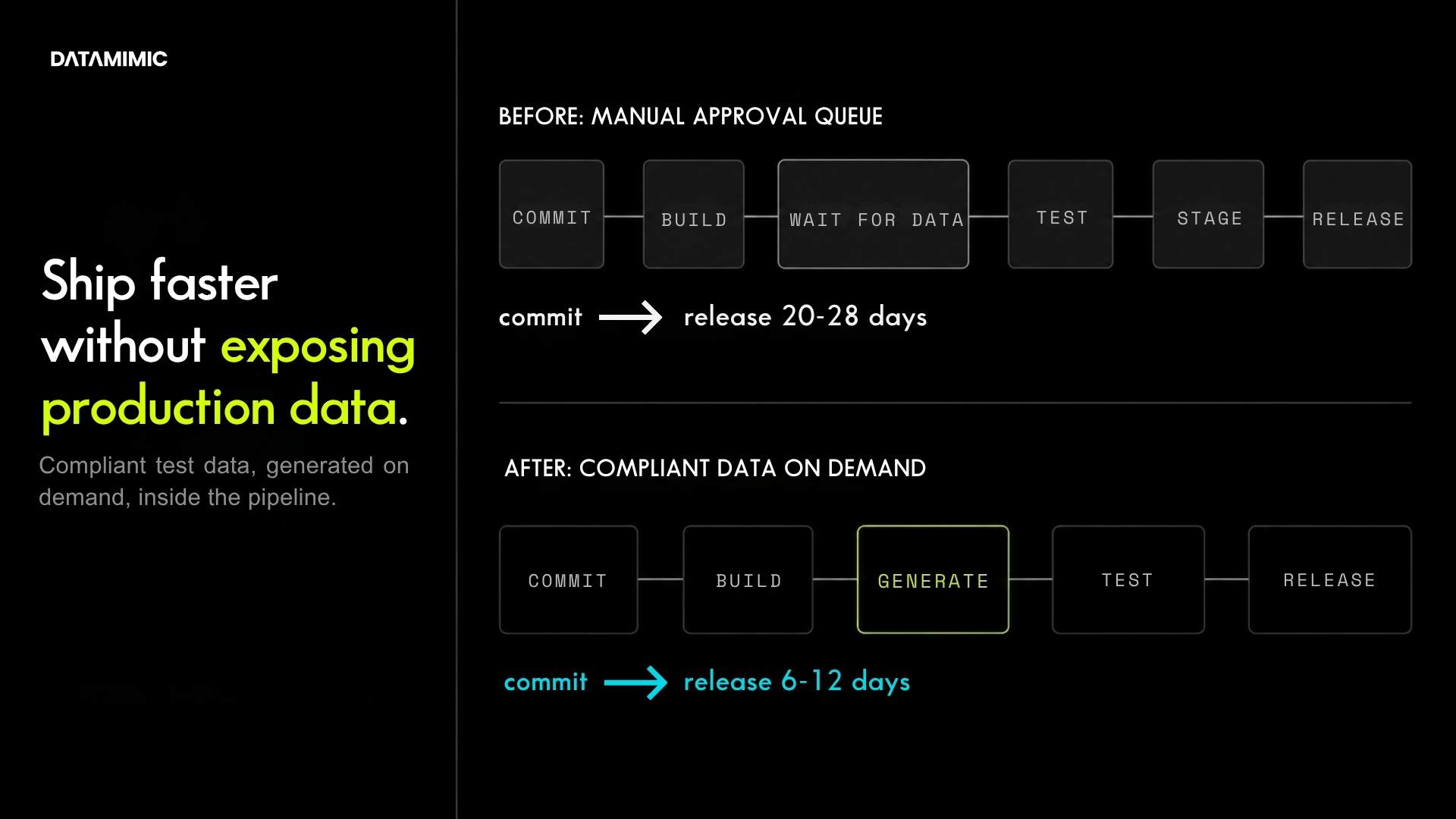
If privacy review is slowing releases, teams are stuck with tightly restricted snapshots, or test environments still cannot cover the scenarios that matter, the synthetic data vs anonymized data decision is no longer theoretical.
It is operational.
Most teams reading this already understand the basic definitions. They know that production-derived de-identification starts from real records and reduces identifiability, often through pseudonymization, anonymization, masking, or generalization. They know that synthetic data is generated rather than copied row by row. The more useful question now is not what these methods are. It is which one creates the better long-term operating model for test data privacy.
That is where the difference becomes material.
One approach tries to make production-derived data safe enough to keep using. The other can reduce the organization’s dependence on production-derived data in non-production environments altogether. For Architects and CIOs designing the non-production data strategy, that is the real decision.

Quick answer: when should you choose anonymized data, synthetic data, or a mix?
Here is the practical answer first.
- Anonymized test data is often enough when you have a narrow, controlled use case, limited access, strong reasons to stay close to historical production patterns, and governance overhead that the organization is still willing to absorb.
- Synthetic test data is often the stronger choice when non-production data access needs to scale, edge cases matter, production history is not enough, or the real goal is to reduce repeated dependence on original records.
- A mixed approach often makes sense when teams are in transition. They may still use anonymized data for tightly constrained workflows, while shifting broader engineering and testing workflows toward synthetic provisioning.
That is the core of anonymized data vs synthetic data.
It is not just a privacy comparison. It is a decision about how you want non-production data to work across the organization.
Synthetic data vs anonymized data: the real difference
Many comparisons focus too much on realism.
Can anonymized data still look production-like? Can synthetic data still preserve enough useful patterns? Those are fair questions, but they are not the most important ones for advanced teams.
The real difference is dependency.
Anonymized test data still starts from original records. Even after fields are masked, generalized, or transformed, the dataset remains production-derived. Its usefulness comes from that lineage, and many of its privacy and governance constraints do too.
Production-derived de-identification spans pseudonymization, which can be deterministic and linkable and may still be personal data under GDPR, and true anonymization, which is irreversible and non-linkable when done effectively. In this comparison, we use “anonymized data” as the broader shorthand to cover both, following the most common search framing.
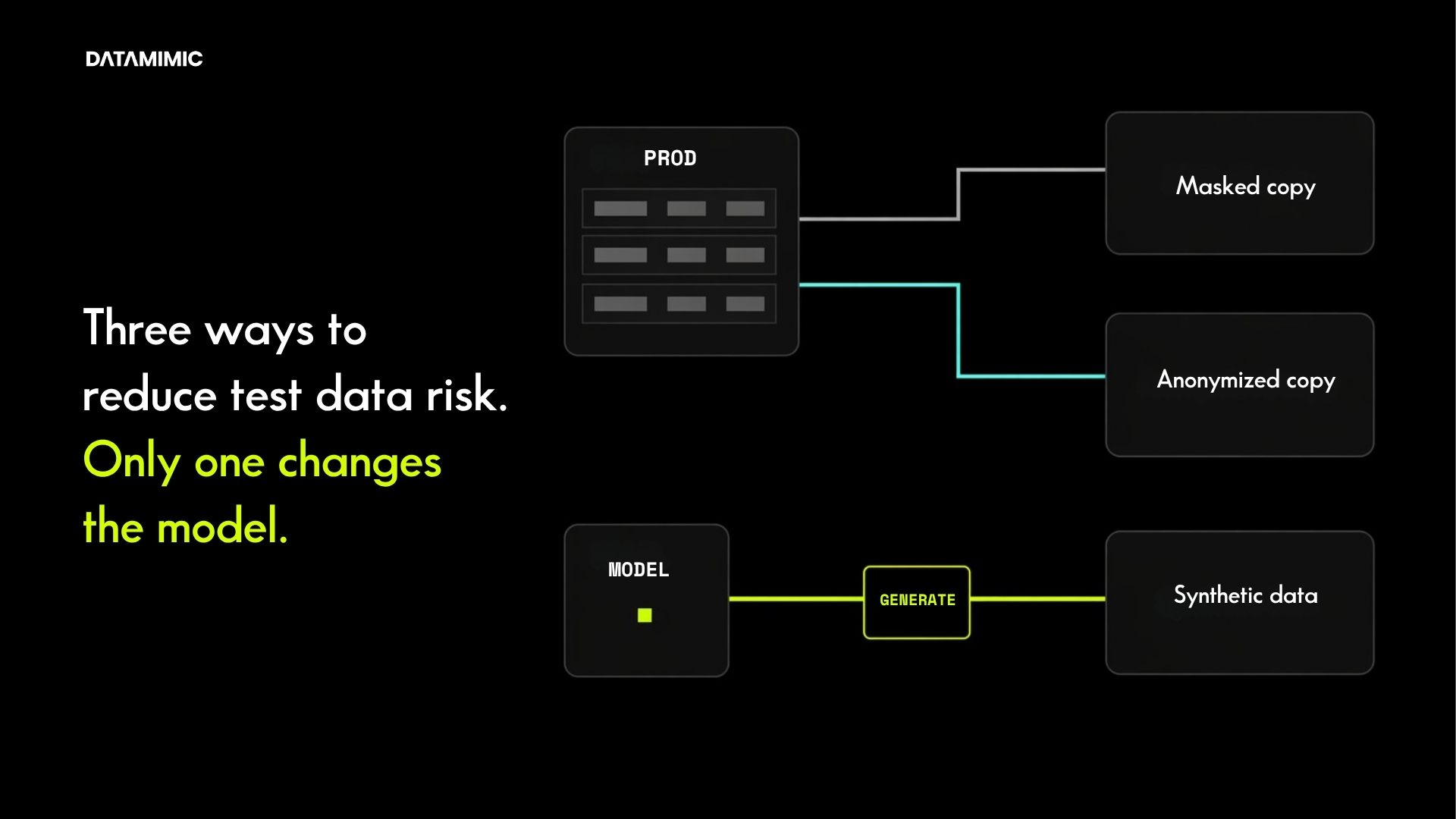
Synthetic test data changes the starting point. Instead of asking how far a copied dataset can be transformed before it becomes usable and acceptable, it asks whether a new dataset can be generated to preserve utility without carrying original records forward in the same way.
That is why the privacy model changes.
As the UK ICO notes, anonymisation is not simply about removing direct identifiers. It is about whether a person can still be identified, singled out, or linked back through context and residual structure. Read the ICO guidance on effective anonymisation. European guidance has made the same point for years, emphasizing the risks of singling out, linkability, and inference when evaluating anonymization effectiveness. See Opinion 05/2014 on Anonymisation Techniques (Article 29 Working Party, carried forward in EDPB guidance)
That is why re-identification risk matters so much in this comparison.
The question is not just whether obvious identifiers were removed.
It is whether the remaining dataset still creates enough residual exposure, contextual identifiability, and governance burden that the workflow continues to be expensive to control.
A side-by-side comparison for architects and decision-makers
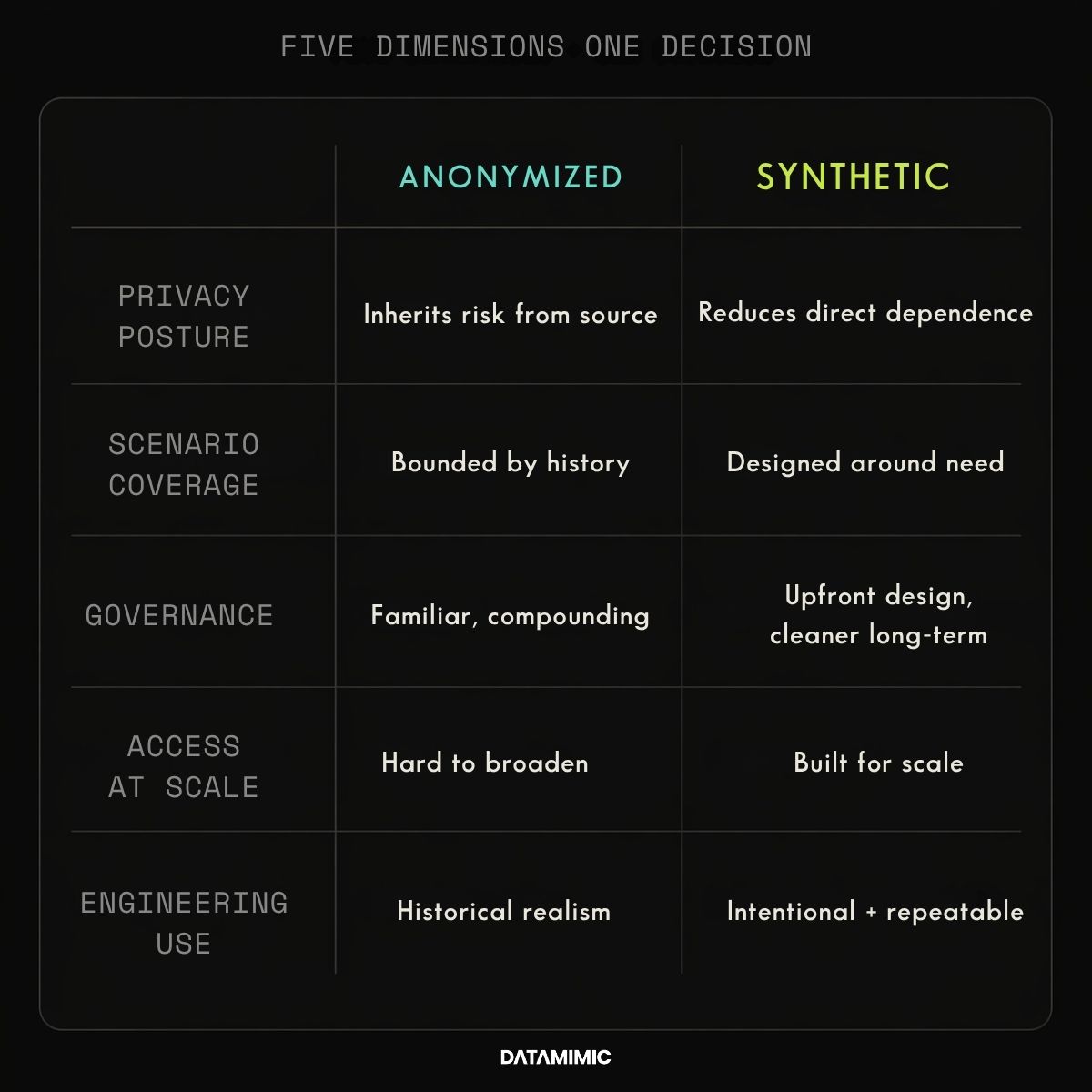
When teams compare synthetic data vs anonymized data, these are usually the dimensions that matter most:
- Privacy posture: Production-derived de-identified data reduces exposure around real records, but it still inherits risk from the fact that it begins with real records. Synthetic data can reduce direct dependence on those records, but it should not be treated as automatically risk-free. Even the ICO notes that synthetic data may or may not be anonymous, depending on how it is generated and what it preserves. See the ICO glossary.
- Scenario coverage: Anonymized data is bounded by production history. It reflects what already happened. Synthetic data can be designed around what teams need to test, including negative paths, rare combinations, incomplete states, and edge cases that do not show up often enough in real data.
- Governance overhead: Anonymized data often looks simpler at first because the workflow is familiar. But every refresh, expansion, access request, or reuse of production-derived data can create more review and more operational friction. Synthetic data usually requires more design discipline upfront, but can create a cleaner long-term provisioning model.
- Scalability of access: Anonymized data can work in tightly controlled environments. It becomes harder to manage when more engineers, testers, vendors, or parallel environments need access. Synthetic data is often more attractive when safe access has to scale.
- Usefulness for engineering: Anonymized data can preserve historical realism. Synthetic data can be more intentional. For many teams, that becomes the deciding factor because useful test data is not just data that looks real. It is data that helps teams recreate the conditions they actually need to test.
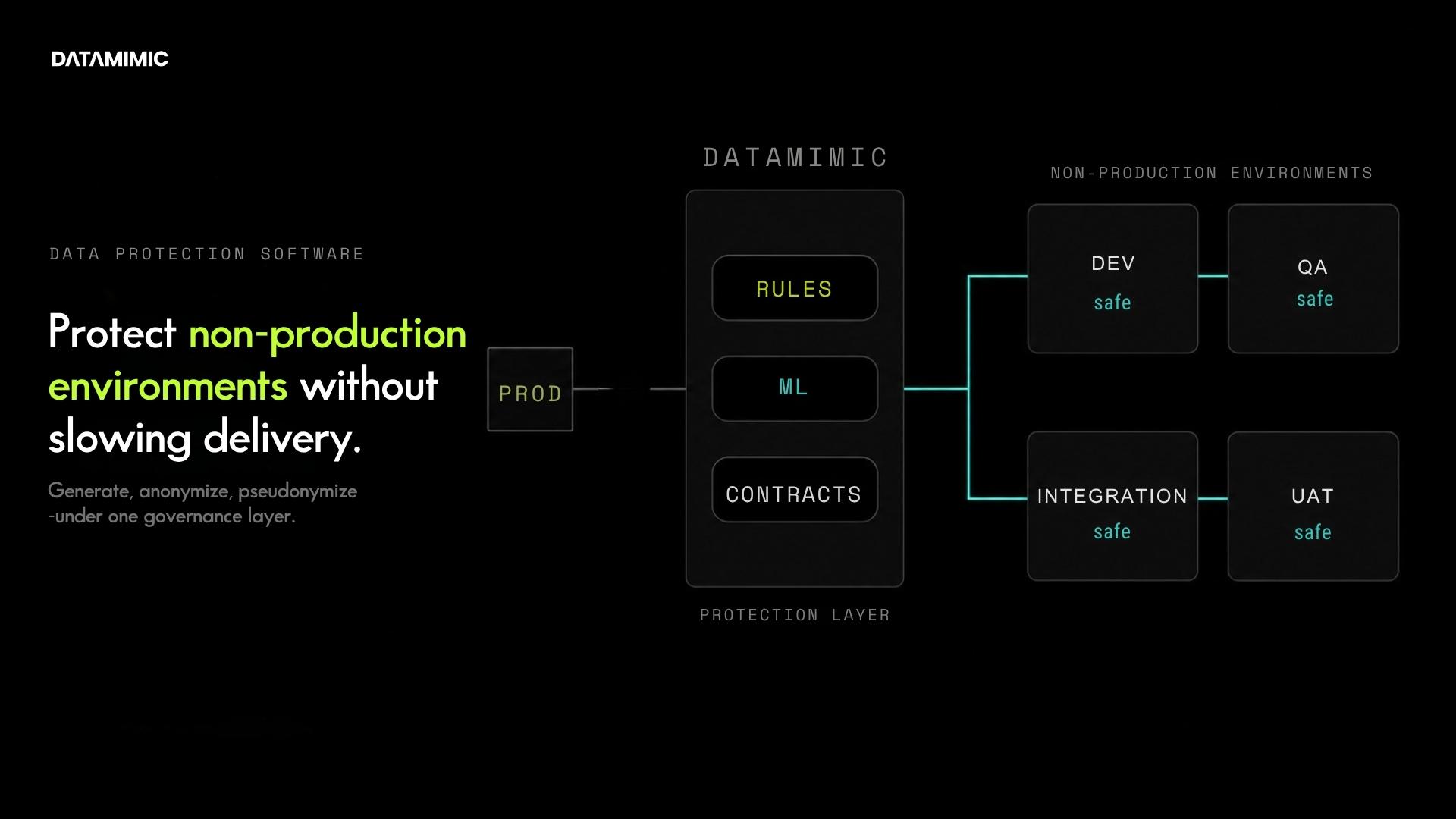
- Architectural fit: Anonymized data keeps the same provisioning topology: production extraction, transformation pipeline, governance gateway. Synthetic data lets you remove that whole flow from non-production environments, replacing extraction with model-driven generation. For Architects evaluating long-term maintainability, that simplification compounds.
- Regulatory status: Pseudonymized production-derived data remains personal data under GDPR. Truly anonymized data, if re-identification risk is sufficiently mitigated, may fall outside GDPR scope. This distinction affects governance overhead.
When anonymized test data is still the right choice
There are still cases where anonymized test data is the right answer.
It can work well when teams need a production-derived dataset for a narrow, controlled purpose, such as a limited validation flow, a tightly restricted UAT environment, or an internal workflow where access is closely governed and data refreshes are infrequent.
It also makes sense when the organization is trying to improve the safety of an existing copy-based workflow without redesigning the workflow completely.
In other words, anonymization can be a pragmatic step when the objective is local risk reduction.
That is different from building a long-term, scalable non-production data model.
The limitation is that anonymized data remains tied to the source it came from. It inherits historical patterns, historical gaps, and historical blind spots. It also keeps the organization in an ongoing posture of managing exposure around production-derived assets rather than moving beyond them.
That is why anonymization often works best as a constrained operating choice, not always as the end state.
Five signs your team has outgrown anonymized data

This is usually where the decision becomes clearer.
1. Privacy review is slowing delivery
If every refresh or reuse of anonymized data triggers approvals, exceptions, or environment restrictions, the workflow may still be too dependent on production-derived assets.
2. Teams need broader non-production access
What works for a small, tightly controlled group often breaks once more developers, testers, analysts, and partners need access across multiple environments.
3. Production history does not contain the scenarios you need
A dev team may need negative paths that real history does not provide. A QA team may need to recreate the same failed condition repeatedly. A fintech team may need to test fraud, payments, and reporting together, even when production data does not contain the right mix at the right time.
4. The real problem is no longer only privacy
If the team is also struggling with repeatability, cross-environment consistency, or test data supply speed, then the decision is moving beyond privacy into operational reliability. That is where concepts like deterministic test data become important.
5. Governance effort keeps compounding
If each new environment, new team, or new use case creates another round of data handling complexity, anonymization may still be reducing exposure while failing to simplify the operating model.
When several of these signs are present, synthetic test data usually becomes the stronger long-term direction.
Where synthetic test data becomes the stronger choice
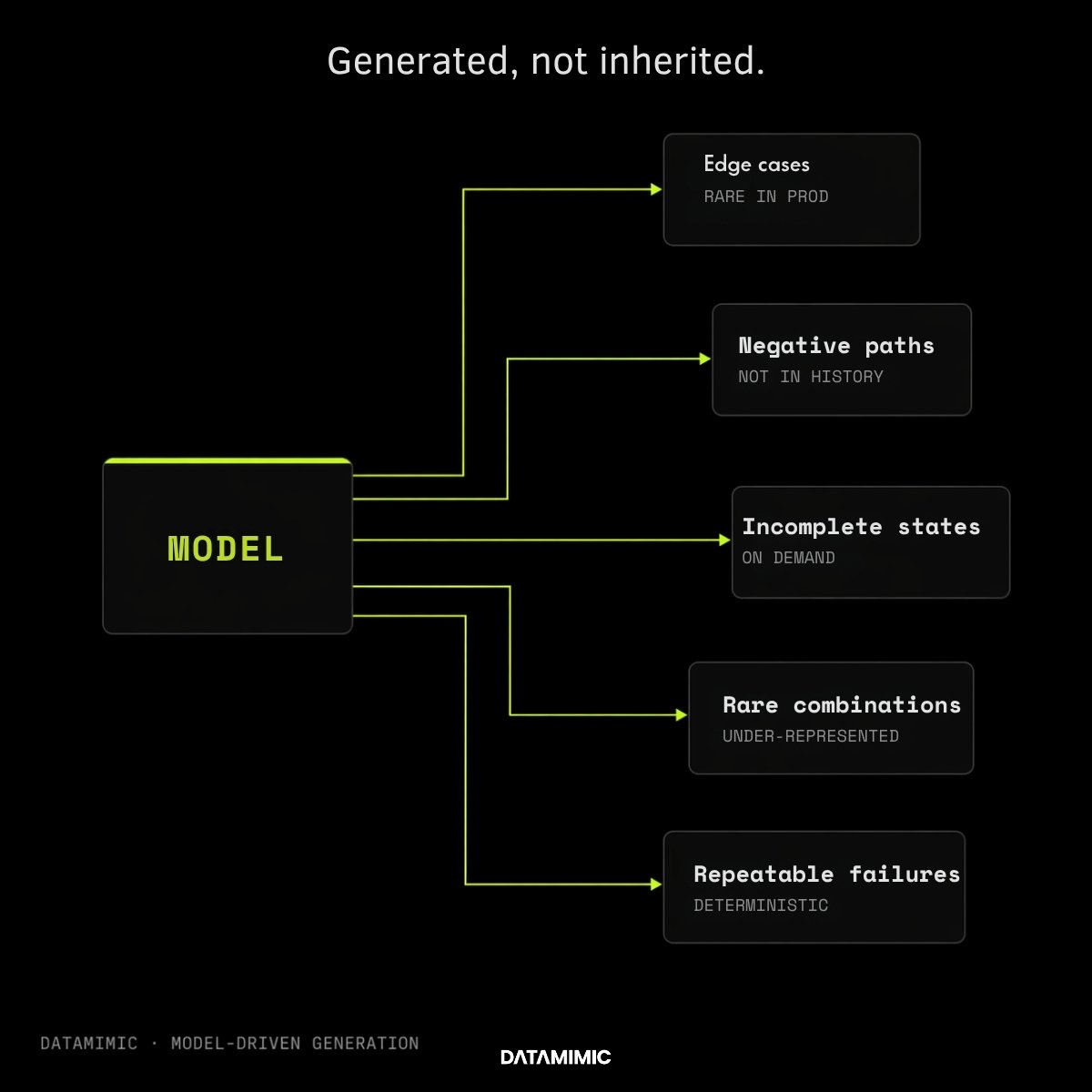
Synthetic data becomes materially more attractive when the organization needs more than a safer copy.
That is usually the case when:
- teams need to generate scenarios that production history does not conveniently contain
- privacy-safe access has to scale across more users and environments
- refreshes need to happen more often
- delivery teams need faster, more repeatable provisioning
- edge cases matter as much as historical realism
- the broader objective is to reduce dependence on original records in engineering workflows
This is where synthetic test data has a strategic advantage.
It is not limited to what already happened. It can be shaped around what needs to be tested.
That matters in very practical situations. A fintech team may need to test fraud events, payment flows, reporting dependencies, and broken states together. A QA lead may need the same failure to be recreated across multiple environments. A compliance team may only allow masked or anonymized snapshots in highly restricted environments, while broader engineering still needs safe and useful data. A development team may need to generate rare negative conditions that production history simply does not contain.
These are not unusual edge cases. They are often the actual work.
That is why the better question is not whether synthetic data can look realistic. It is whether it can generate data that is useful enough for the engineering task while improving the privacy model at the same time.
Not all synthetic data is good enough for serious testing
This is where many evaluations go wrong.
Teams sometimes compare strong anonymization workflows to weak synthetic examples, then conclude that synthetic data is only good for demos or toy environments. That is not the right comparison.
The right question is whether the synthetic approach is production-grade enough for the environment it is meant to serve.
For evaluation-stage buyers, the important questions are more specific:
- Does the platform preserve referential integrity where it matters?
- Can it maintain relationships across systems, not just tables?
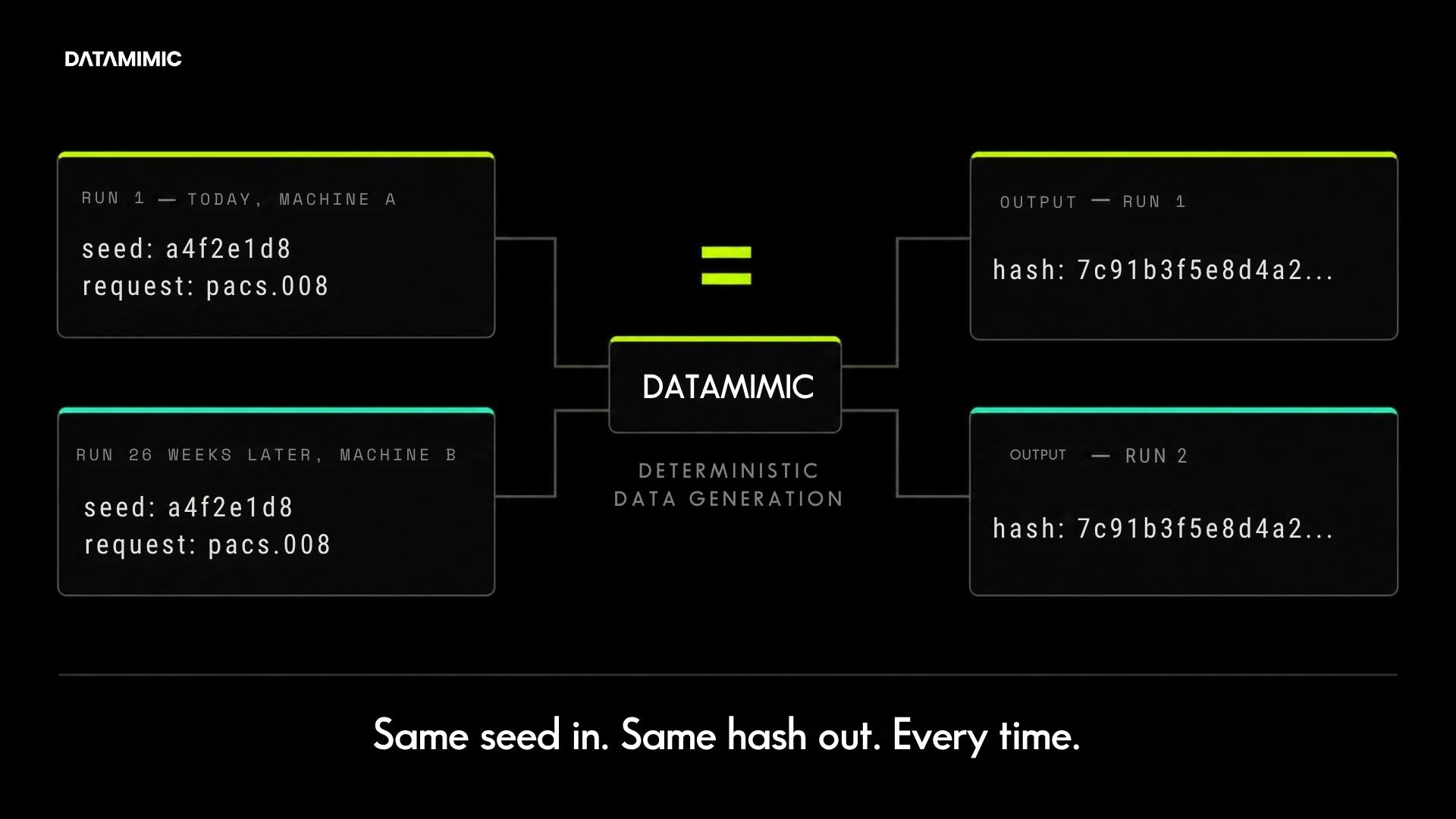
- Can it generate repeatable or deterministic outputs when reproducibility matters?
- Can it handle structured and nested formats, not just flat relational data?
- Can it fit CI/CD and engineering workflows instead of becoming a manual side process?
- Can it provide enough governance and auditability for regulated teams?
These are buying questions, not abstract technical questions.
They are also where DATAMIMIC’s differentiation starts to matter. Synthetic data only becomes strategically valuable when it is more than plausible fake values. It needs to be model-driven, usable in real engineering workflows, and strong enough to support complex systems. DATAMIMIC’s documentation on model-driven generation, complex JSON/XML handling, GDPR-oriented capabilities, and workflow integration is relevant here because it reflects what advanced teams should actually verify when evaluating synthetic platforms.
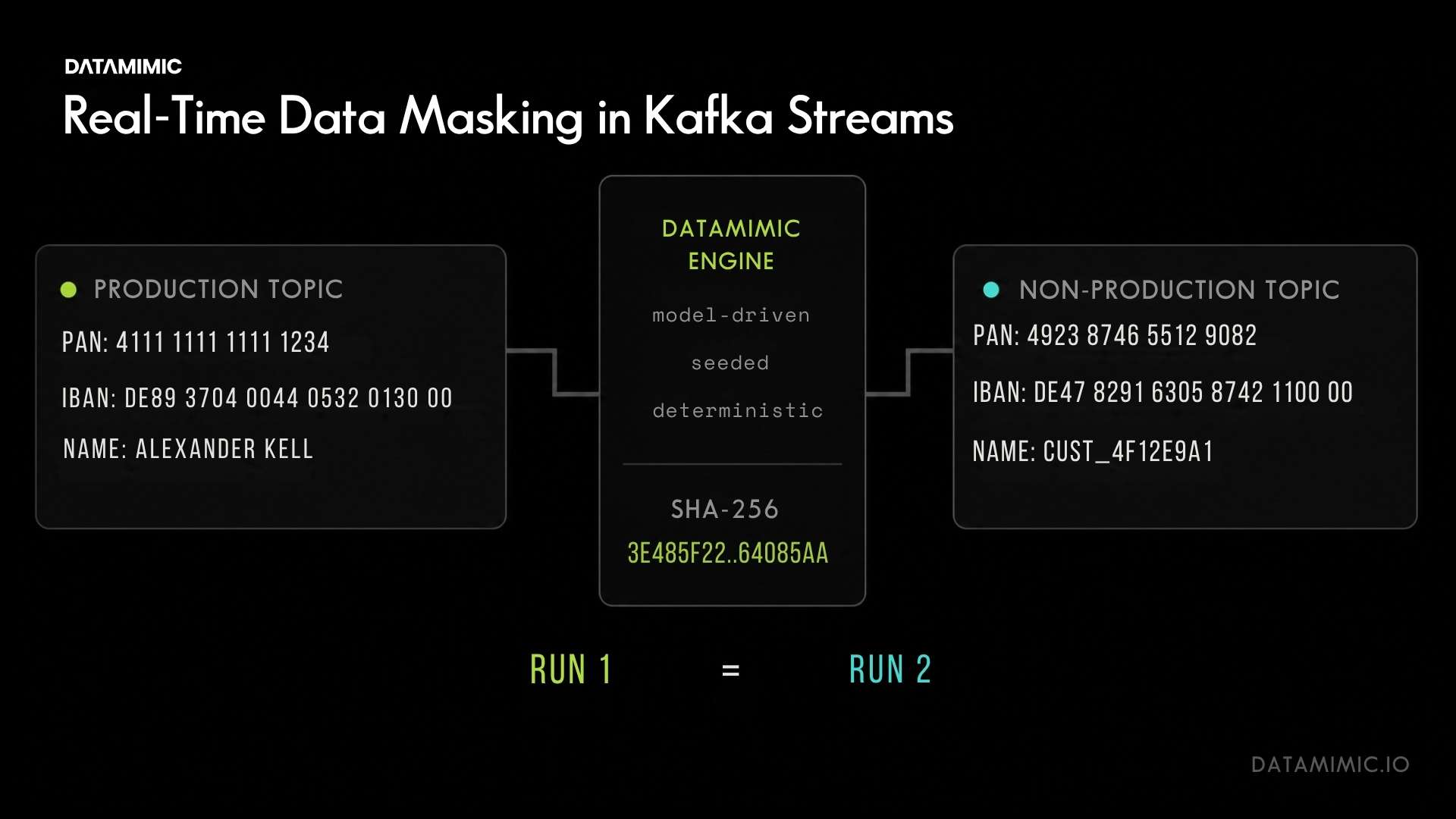
And if you want a concrete example of that kind of evaluation in practice, see how a Tier-1 European bank used DATAMIMIC to deliver deterministic test data across Oracle, MongoDB, and Kafka.
A practical recommendation by team maturity
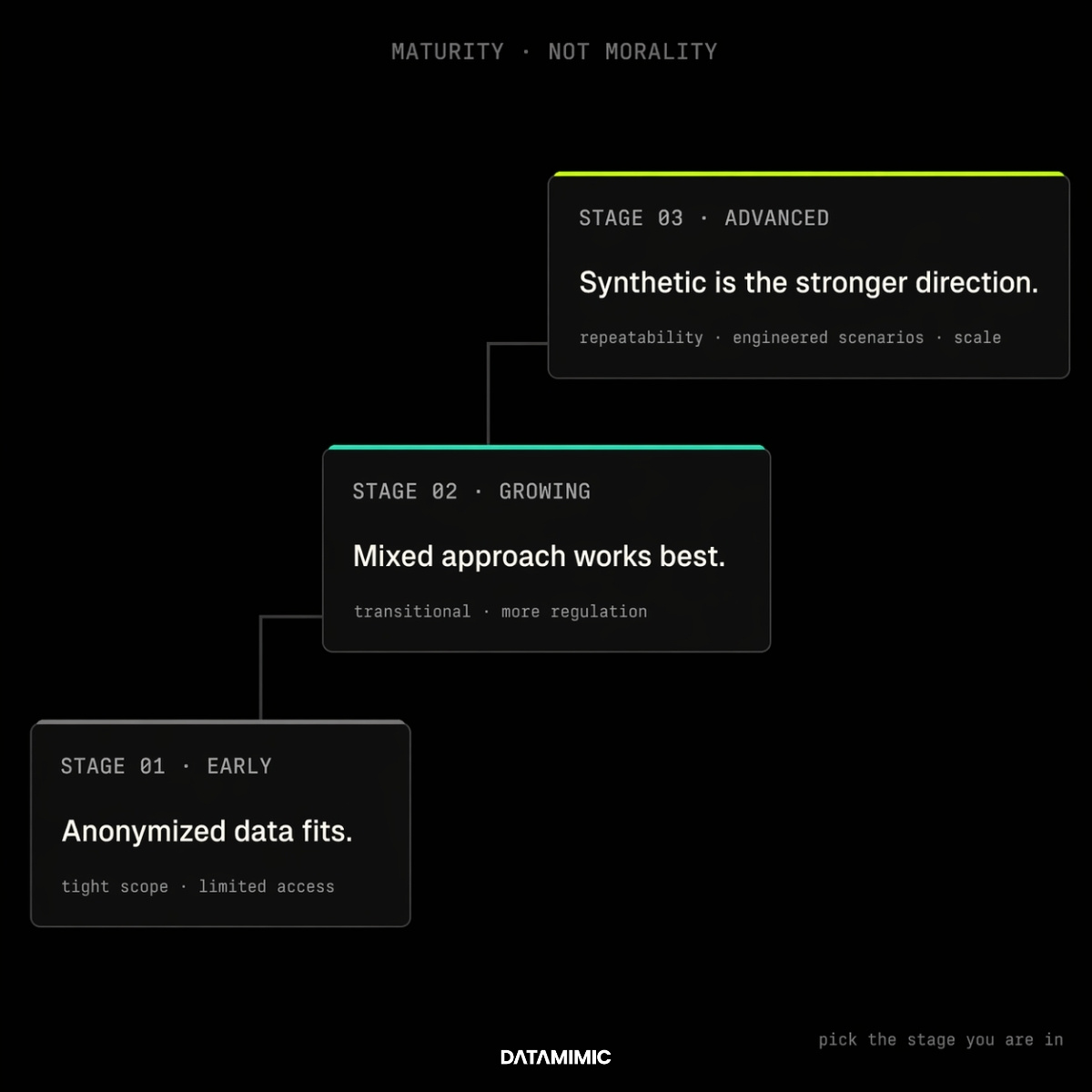
If your team is still early and tightly constrained, anonymized data may be enough for now.
If your team is growing, under more regulatory pressure, or struggling to scale safe non-production access, a mixed model is often the most realistic transition path.
If your challenge now includes repeatability, engineered scenario coverage, broader access, and long-term operational scale, synthetic data is usually the stronger strategic direction.
That is the simplest way to think about synthetic data vs anonymized data.
Anonymization is often a way to harden a copy.
Synthetic data is often a way to reduce the organization’s need for the copy in the first place. Teams do not need to abandon anonymized data overnight. In many environments, it remains useful for tightly controlled workflows. But once privacy review, access scaling, repeatability, and scenario coverage become bigger constraints, synthetic test data usually becomes the stronger long-term direction.
For CIOs evaluating vendor risk, the synthetic path also reduces dependency on production data flows, creating a smaller blast radius if anything goes wrong with the production extraction pipeline.
Final takeaway
For advanced teams, this is not a beginner comparison anymore.
It is a choice between two operating models.
If your main goal is to make a limited production-derived workflow safer, anonymized data may still be the right fit.
If your goal is to improve test data privacy while also scaling non-production access, generating missing scenarios, reducing repeated governance friction, and moving toward a cleaner long-term engineering model, synthetic test data is usually the stronger choice.
If your team is still evaluating all three approaches, including masking, read our guide to data masking vs anonymization vs synthetic data.
And if your challenge is no longer just privacy, but also reproducibility, cross-system consistency, auditability, and edge-case coverage, that is usually the point where DATAMIMIC becomes most relevant.
FAQs
1. What is the real difference between synthetic data and anonymized data?
Anonymized data, used here as shorthand for production-derived de-identification, starts from production records and reduces identifiability through transformation. That may include pseudonymization or true anonymization, depending on whether records remain linkable.
Synthetic data is generated from a model, without copying production records forward. The structural difference is dependency: anonymized data inherits its lineage from production, synthetic data does not.
2. Is synthetic data automatically anonymous under GDPR?
No. The UK ICO explicitly notes that synthetic data may or may not be anonymous, depending on how it is generated and what it preserves. Whether the result qualifies as anonymous depends on whether individuals can still be singled out, linked, or inferred from the output.
3. Can synthetic data fully replace anonymized data?
Not in every case. Anonymized data still fits narrow, controlled workflows where the goal is local risk reduction inside an existing copy-based process. Synthetic data becomes the stronger choice when access has to scale, scenario coverage matters, or the goal is to reduce dependence on production-derived assets.
4. How does synthetic data preserve referential integrity?
Through model-driven generation. When the same model defines customer, account, and transaction entities, the engine generates consistent identifiers across all target systems: Oracle, MongoDB, Kafka, or JSON payloads. The relationships hold because they are defined once in the model, not reconstructed per target.
5. When does it make sense to use both anonymized and synthetic data together?
During transition. Teams often keep anonymized data for tightly constrained workflows (limited UAT lanes, controlled validation environments) while shifting broader engineering and QA workflows toward synthetic provisioning. The mixed approach is a realistic path rather than a rip-and-replace.

September 6, 2025
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly