Home › Real-Time Data Masking in Kafka Streams for Payment Systems
Real-Time Data Masking in Kafka Streams for Payment Systems
Payment systems built on Apache Kafka process millions of transactions carrying Primary Account Numbers (PANs), cardholder names, International Bank Account Numbers (IBANs), and account identifiers. That data replicates across topics, fans out to consumer groups, and lands in analytics pipelines, QA, staging, integration, and UAT environments. Every copy is a compliance liability under Payment Card Industry Data Security Standard version 4.0 (PCI DSS 4.0) and the General Data Protection Regulation (GDPR Art. 5(1)(c) data minimisation and Art. 25 privacy by design). For financial entities, every additional copy also expands the ICT attack surface that the Digital Operational Resilience Act (DORA) expects them to manage. PCI DSS forbids CVV and CVV2 storage after authorization. This article therefore excludes them from scope.
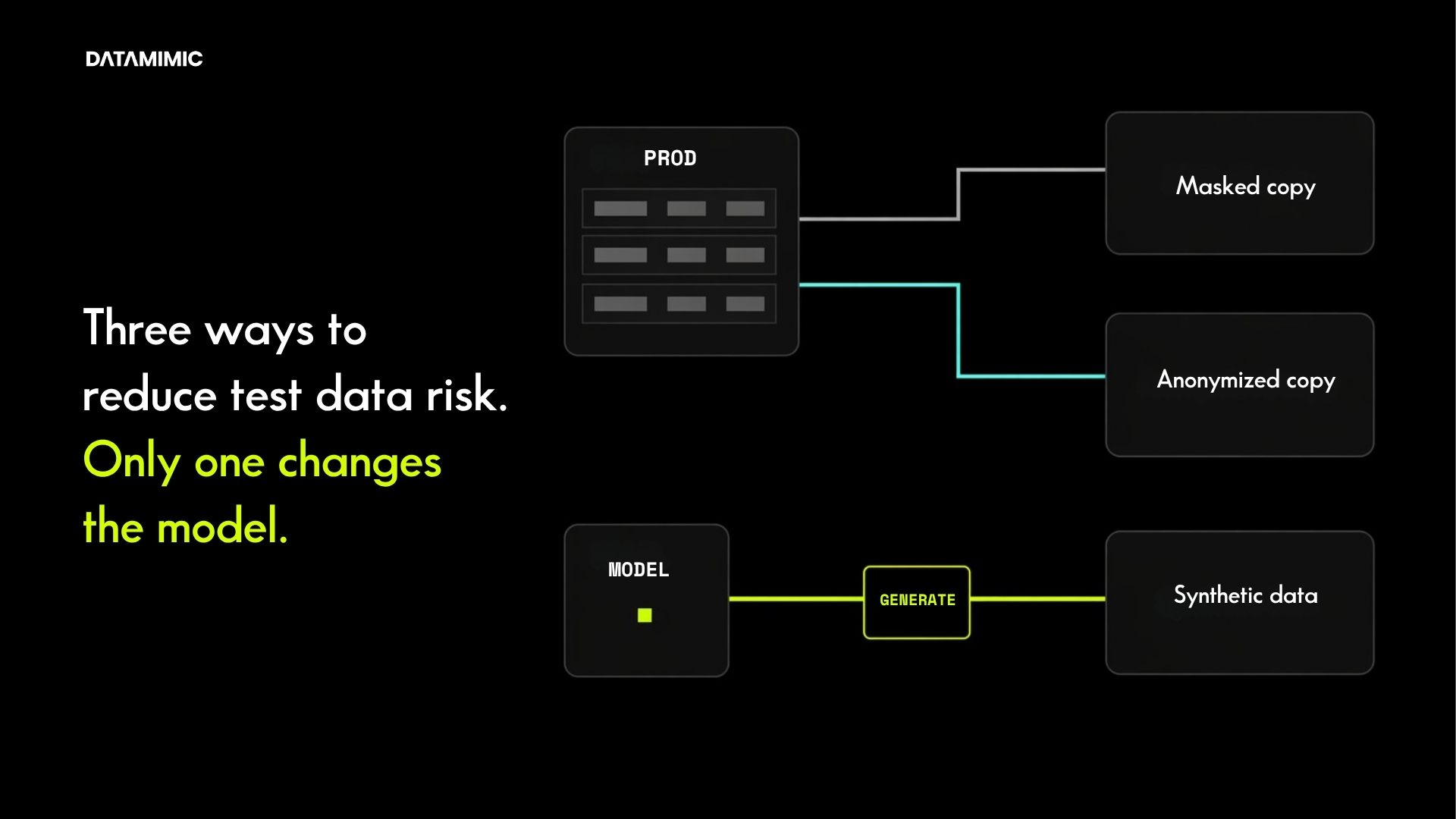
The problem is that non-production environments still need data that behaves like production. Functional, regression, system, and load testing all depend on realistic transaction patterns, valid payment formats, referential integrity, and edge cases that generic synthetic data often misses. Real-time data masking lets non-production environments receive production-shaped data with no real cardholder data: the production PANs, names, and account numbers are replaced before the message leaves the controlled boundary. As a result, engineers, partners, logs, test databases, and third-party tooling never see real cardholder data. Where the masked values must stay linkable across topics, this is pseudonymization under GDPR Art. 4(5): no longer directly attributable, but still personal data under Recital 26. Irreversible anonymization, outside GDPR scope, is a separate mode.
This post covers four areas. First, why streaming Kafka pipelines are harder to de-identify than traditional batch systems. Second, the five de-identification techniques that work at the stream level (tokenization, format-preserving encryption, pseudonymization, field-level masking, and deterministic pseudonymization). Third, the four architectural requirements that separate production-grade tools from one-off scripts. Finally, how DATAMIMIC implements these for regulated payment processors.

June 3, 2026
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly
Why Kafka Data Privacy Is Harder Than Batch Masking
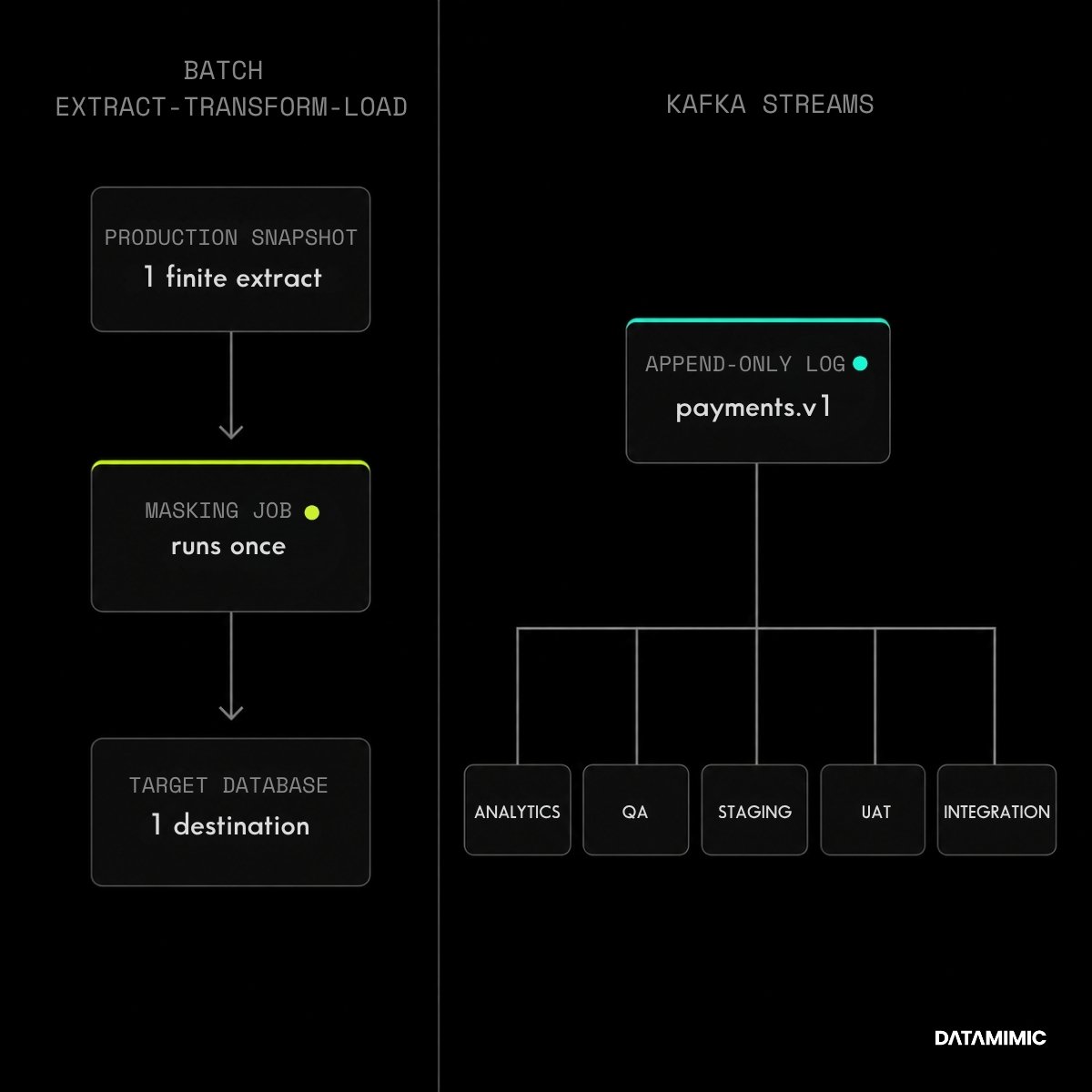
Kafka’s architecture makes cardholder data protection harder than in traditional batch systems such as nightly Extract-Transform-Load (ETL) jobs or batch-mode masking tools like Informatica TDM and IBM Optim. In a batch workflow, teams extract a finite production snapshot, mask it once, write it to a target database, and let downstream systems read from that masked copy. The process has a clear cutoff: the data has a beginning, an end, and a controlled destination.
Kafka does not work that way. Payment events are written to an append-only log, replicated across brokers, consumed by multiple downstream services. Teams then copy these events into analytics, QA, staging, integration, and UAT environments. A single message carrying a PAN, cardholder name, or account identifier quickly becomes many copies across many systems. Unless de-identification happens upstream, the full-fidelity Personally Identifiable Information (PII) is present in the stream and readable by every consumer group.
Existing Kafka controls help, but they do not fully solve this problem. Confluent Client-Side Field-Level Encryption (CSFLE), Confluent Schema Registry data contracts and tagging (the policy attachment point for CSFLE rules), and Single Message Transforms (SMT) each address part of the risk. Apache Kafka provides no native, broker-level, policy-driven de-identification. Transformation happens at the producer, in Kafka Connect via Single Message Transforms, in a stream processor, or at a gateway. The built-in MaskField SMT either nulls a field to its type default or replaces it with one static literal across every record, so it produces neither format-preserving values nor distinct, referentially-consistent pseudonyms.
GDPR Article 17 (right to erasure) makes this harder because Kafka’s append-only log makes record-level deletion impractical. Teams reach for three indirect mechanisms:
- Crypto-shredding: encrypting each record’s sensitive fields with a per-subject key and destroying the key on erasure, leaving the bytes mathematically unreadable.
- Tombstone events on compacted topics: publishing a null value for a given key so the compactor drops the prior record on the next cycle. This applies only to keyed compacted topics, which payment event streams rarely are, since those are time-retention append logs.
- Retention minimization with producer-side pseudonymization: shortening
retention.msso payloads age out within hours, paired with replacing identifiers before the message ever reaches the broker.
For Kafka-based payment pipelines, data protection must happen at the stream level. There are three practical places to apply it: at the producer before the message enters the topic, inside a stream processor such as Kafka Streams or Flink, or at a gateway/proxy layer before consumers receive the payload. Once payment data has reached non-production systems, the surface area is too large to clean up reliably.
De-identification Techniques for Streaming Payment Systems
Not every data protection method fits streaming payment workloads equally. Encryption (at rest, in transit, or field-level) and access control are the primary controls for securing payment data in flight. De-identification serves a different purpose: making data safe for non-production use cases like testing, analytics, and partner integrations where the original values must not be exposed. The choice between the techniques below depends on whether downstream consumers need format consistency, cross-topic referential integrity, or statistical fidelity.

Tokenization
- Customer email
[email protected]becomescust_4f12e9a1. - IBAN
DE89370400440532013000becomestok_ib_9c1e7b32. - PAN
4111 1111 1111 1234becomestok_pan_5a3f7e9b.
- Vault-based tokenization. The original-to-token mapping is stored in a centralized token vault, a hardened, access-controlled database that authorized callers can query to retrieve the original value. Pros: fully reversible by authorized systems; useful when production lookups are required. Cons: every read is a lookup hop, which adds latency and concentrates risk in one system.
- Stateless tokenization. The token is generated deterministically from the input using an HMAC (Hash-based Message Authentication Code: a one-way function that takes a value and a secret key, and always returns the same output for the same inputs) or a deterministic cryptographic function. Pros: no vault, no lookup latency, consistent tokens across topics. Cons: HMAC-based tokens are one-way; reversible schemes such as FPE are a different tool with different scope. For PAN specifically, PCI DSS 4.0 Requirement 3.5.1.1 (mandatory since 31 March 2025) requires a keyed cryptographic hash such as HMAC, with managed keys. A plain unkeyed hash no longer renders a PAN unreadable for PCI purposes. Deterministic forward, not invertible: that is the property non-production environments want.
Format-Preserving Encryption (FPE)
FPE applies encryption while preserving the data structure. A 16-digit PAN encrypts to another 16-digit string that preserves field length and, in some implementations, checksum validity. For PAN that means Luhn compatibility: the masked card number still passes the Luhn algorithm, the check-digit formula that downstream payment systems use to detect typos, so test environments do not need to disable validation logic. Luhn preservation is not automatic in FPE: implementations achieve it by recomputing the check digit after encryption, or by cycle-walking until the output is Luhn-valid. Downstream systems continue to function without schema changes.
Examples:
- PAN
4111 1111 1111 1111becomes4923 8746 5512 9082(Luhn-valid, same length). - German tax ID
12345678901becomes47829163058(same 11-digit format). - US Social Security Number
123-45-6789becomes847-29-1635(same format).
FPE is reversible with the correct key. That distinction matters for compliance scoping: encrypted data may still fall under PCI DSS scope depending on how the key is managed.
Pseudonymization
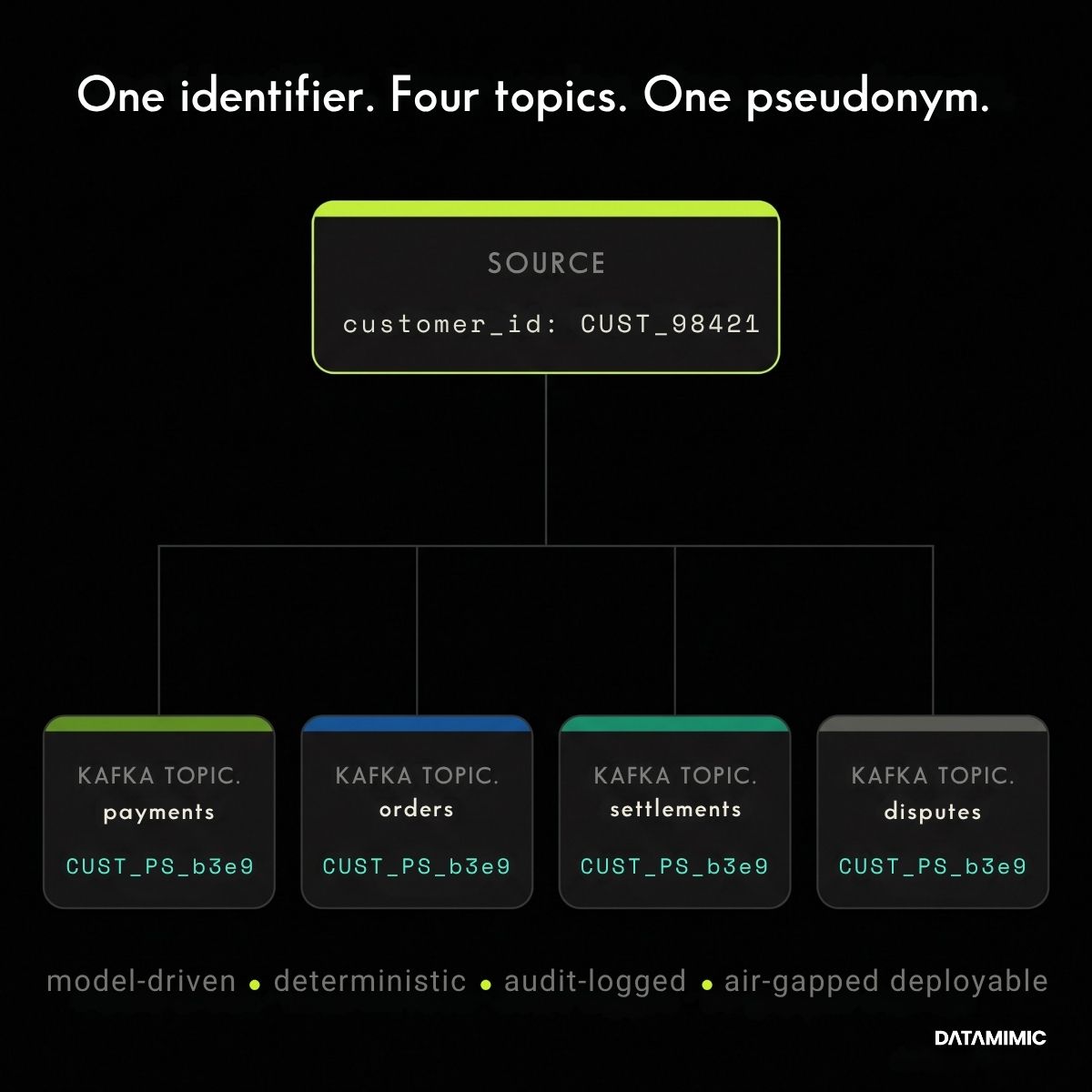
Replaces identifiers with surrogate values while preserving referential integrity across topics. If a customer ID appears in payments, orders, and service-events topics, the pseudonymized customer ID remains consistent across all three. Without this, joins downstream break and analytics become meaningless. Consistency holds because the pseudonym is keyed to the identifier value itself, not to its position or surrounding record, so the same value maps to the same token wherever it appears.
Examples:
- Customer ID
CUST_98421becomesCUST_PS_b3e9in every topic where it appears. - Merchant ID
M-7841resolves toM-PS-c12ain the payments topic, the settlement topic, and the dispute topic. - Device fingerprint
dev_aab12cresolves todev_PS_e731consistently across the fraud and analytics pipelines.
Homegrown scripts typically handle pseudonymization correctly for a single topic, then lose consistency the moment the same identifier needs to resolve across multiple streams. In a payment system, a single transaction touches several topics, so this is the most common failure mode.
Field-Level Masking
Applies masking rules per field, typically at the consumer or proxy layer. Different consumer groups see different levels of masking:
- The analytics team sees masked PAN (
****-****-****-****) and redacted customer names. - The fraud detection service sees tokenized account IDs with preserved transaction amounts.
- The QA team sees fully de-identified records that look real but carry no production-derived values.
The advantage is flexibility. Different consumer groups can receive different visibility levels into the same payment event stream without duplicating infrastructure. This approach is commonly used in PCI DSS data masking programs where analytics, fraud detection, operations, and QA teams each require different levels of access to payment data. The risk is policy sprawl. Managing per-consumer masking rules across dozens of topics and consumer groups requires centralized policy governance, not per-application configuration.
Deterministic Pseudonymization
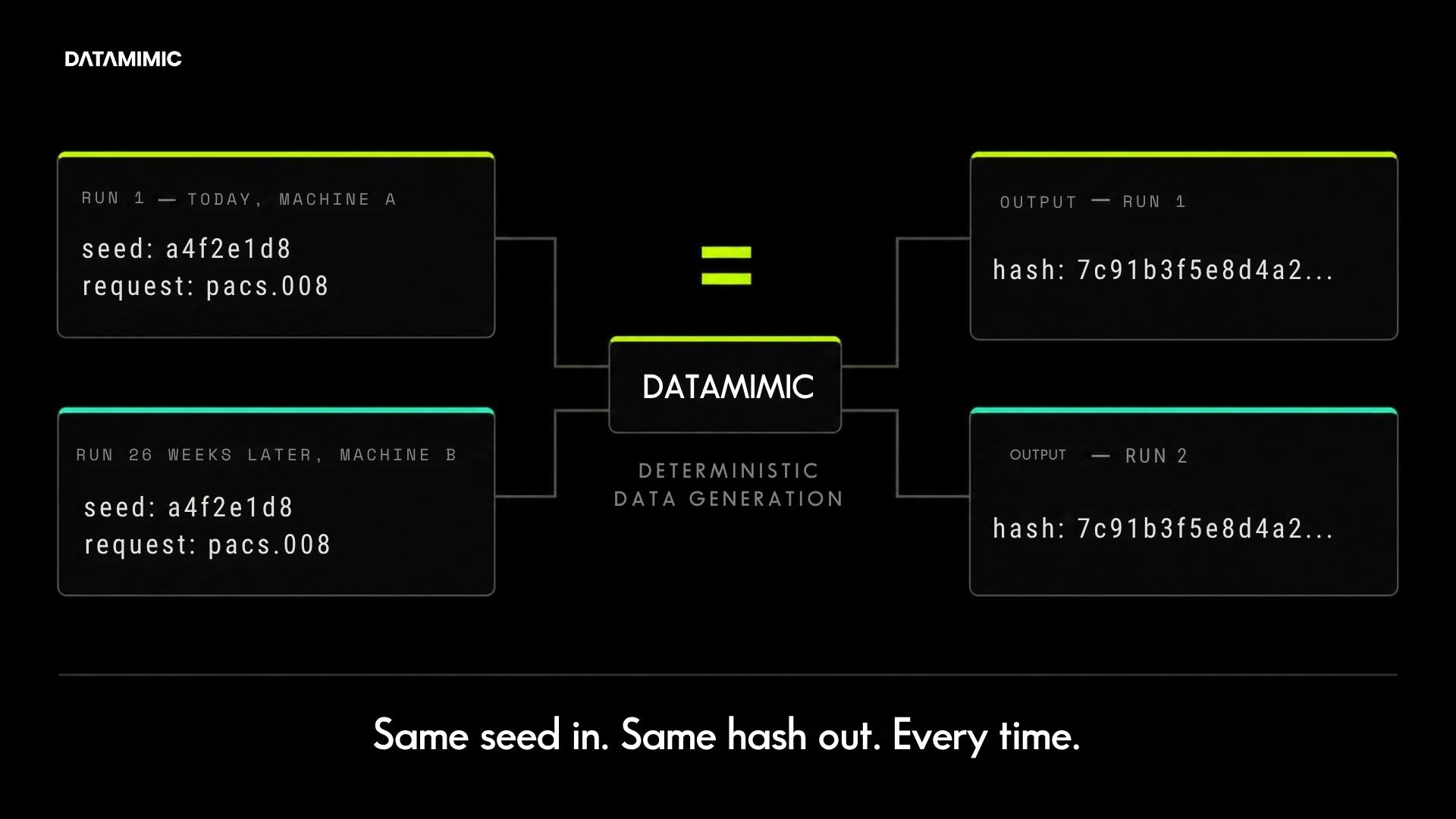
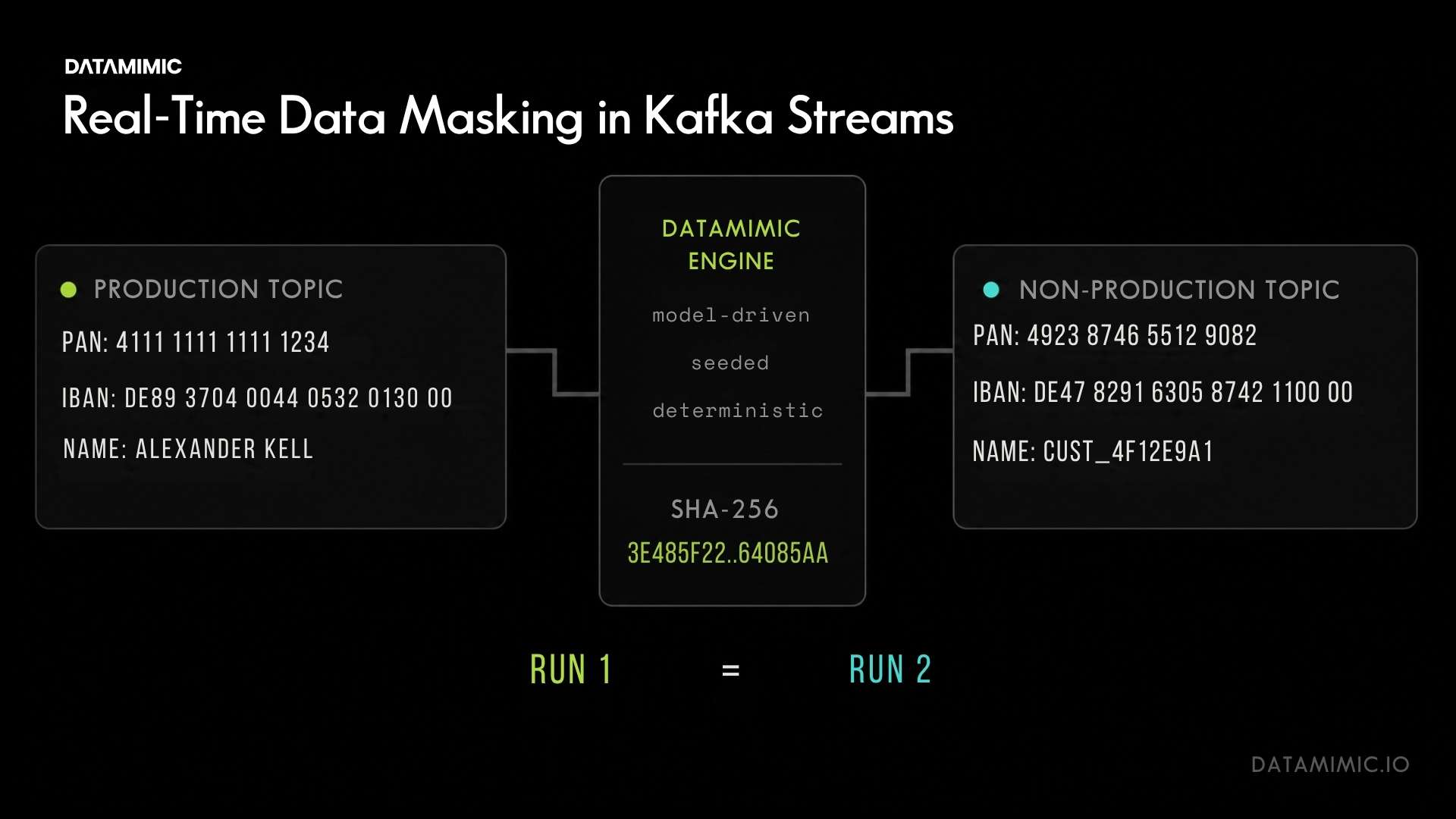
Given the same seeded model and the same engine version, masked output is byte-identical across runs, hosts, and environments. A seeded pseudonymization function applied to a PAN on Monday produces the same token on Friday, on a different host, in a different CI pipeline run. Drop the seed and the engine deliberately produces non-deterministic, CSPRNG-based output with no reversible field-level mapping, for privacy-maximized one-time deliveries. No middle ground, no implicit mode switch.
Examples:
- PAN
4111 1111 1111 1111always pseudonymizes to4923 8746 5512 9082, regardless of run. - A Monday run and a Friday rerun of the same regression test produce byte-identical pseudonymized datasets, so a failed test can be diffed against the prior pass.
- Two parallel CI workers process disjoint partitions of the same stream and emit per-record outputs that join cleanly downstream. Identifier fields (customer ID, merchant ID, IBAN, PAN) are keyed to the field value through a stateless deterministic function, so the same identifier resolves to the same pseudonym across every topic. Generated and statistical fields, which carry no cross-topic identity, are keyed to the record’s content and position in the source stream for replay-stability. Neither is keyed to which worker processed the record.
Teams that need reproducible test datasets, audit traceability, and regression testing against consistent pseudonymized data cannot use statistical or random anonymization. It breaks all three. Deterministic Kafka PII masking is required wherever downstream analytics, reconciliation, replay testing, or cross-topic joins depend on referential consistency.
For Kafka-based payment systems, deterministic pseudonymization is the baseline. The harder problem is combining it with cross-entity referential integrity, domain-aware generation for regulatorily defined field formats (IBAN check digits, SWIFT field lengths, EDIFACT segments), and a verifiable audit trail. That combination is where most homegrown approaches and single-purpose tools fall short.
Advanced Determinism and Production Requirements
Streaming normally defeats reproducibility: parallel consumers, partition rebalancing, and retries can make each run produce a different message order. The DATAMIMIC engine sidesteps this with two seed regimes, neither tied to consumer state or worker identity. Identifier fields are keyed to the field value through a stateless deterministic function, which is what holds the same pseudonym consistent across topics. Generated and statistical fields are keyed to the record itself: a seedless xxh3-64 hash of the record’s canonical content identifies it, then the setup seed and the record’s source position are folded into the RNG seed in the execution layer. The hash is deterministic across processes, unlike Python’s per-process-salted hash() for strings. This positional regime is the Enterprise execution layer for multi-process targets. The single-process CE proof below uses a different mechanism: an integer-seeded random.Random per record. Same contract, two layers.
Two consequences follow:
- Worker-independent output. The same input record produces the same per-record output regardless of which worker, which partition, or which retry processed it. Re-keying a Kafka topic does not require re-coordinating workers.
- Exact per-record replay. Re-running the masking job over the same source partitions, even at a different parallelism or with a different consumer-group layout, produces a topic with the same per-record payload. Broker-level message order may differ; the per-record content does not.
This is the property that lets a downstream Flink or Kafka Streams join in QA reproduce a production result without snapshotting partition state. It is also why distributed determinism is part of the DATAMIMIC Enterprise execution layer, not something a homegrown SMT delivers consistently.

What Real-Time Data Masking Requires in Production-Grade Pipelines
Before the requirements: why mask payment data in real time instead of waiting for a nightly batch job?
- Test data freshness. QA, staging, and UAT teams need data that reflects what production looks like today, not last quarter. Nightly batches miss new merchant categories, new fraud patterns, and new ISO 20022 message variants.
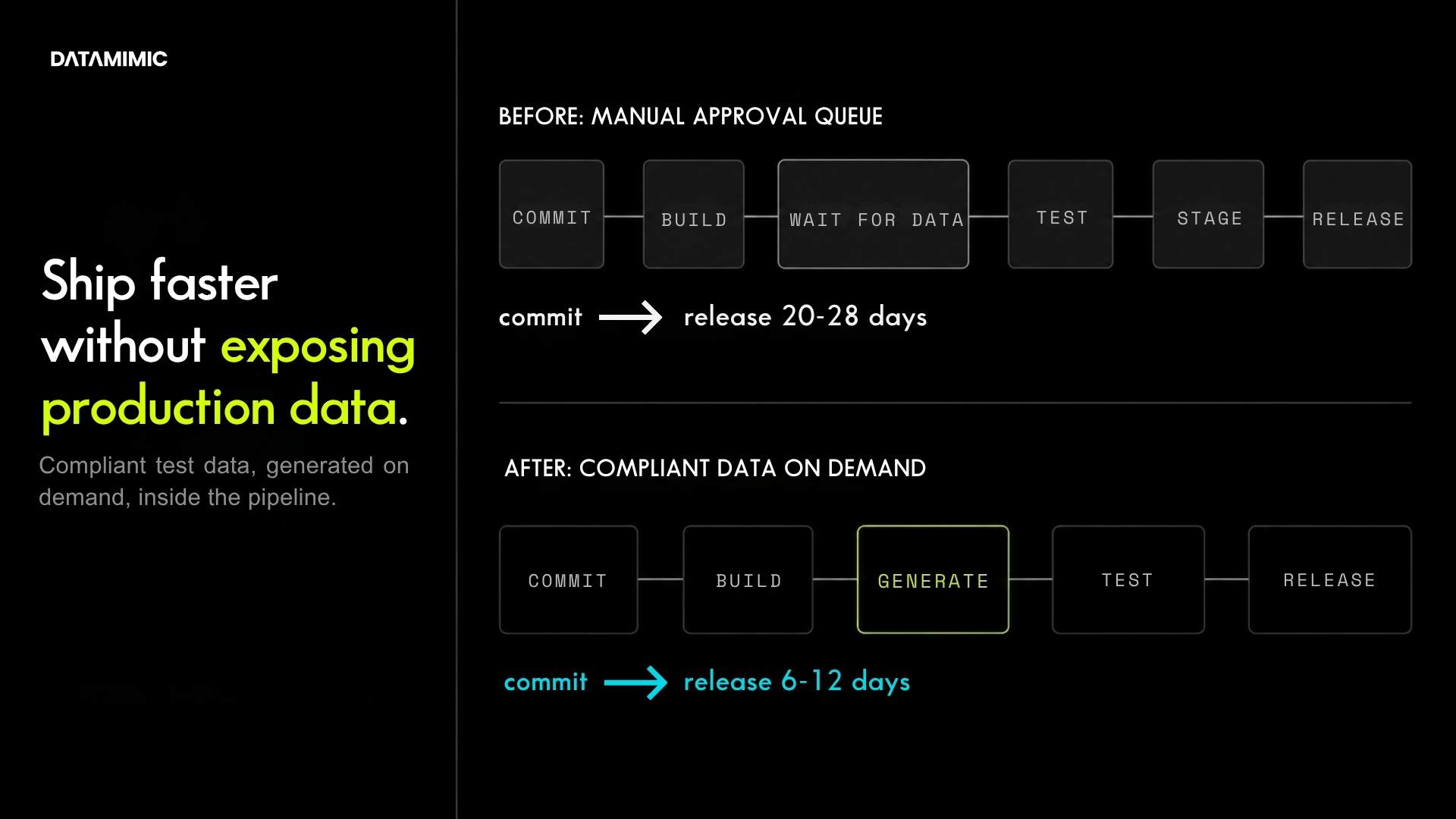
- Faster release cycles. Engineering teams blocked waiting for a refreshed test environment ship slower. Stream-level masking decouples non-production data refresh from batch windows.
- Audit defensibility. When a regulator asks “what data did you use to validate this release,” a deterministic, audit-logged stream is a clean answer. A nightly script with manual touchpoints is not.
- Containment. Every additional hour that raw PII sits in a non-production system is additional exposure. Real-time masking shortens that window to near zero.
Applying these techniques in a Kafka pipeline that meets the bar above imposes four architectural requirements that separate real-time data masking tools from batch-oriented solutions:
- Latency: De-identification must happen in-stream without measurable delay. For payment pipelines handling pacs.008 (ISO 20022 credit transfer message) or SWIFT MT messages at thousands of transactions per second, every millisecond of added latency compounds across the pipeline.
- Cross-topic consistency: Pseudonymized values must stay consistent across Kafka topics and downstream consumers. A tokenized customer ID in the payments topic must resolve to the same token in the orders topic. Without this, referential integrity across the event stream is destroyed.
- Auditability: Each de-identification run needs a traceable record: task ID, model and engine version, timestamp, content hash, and configuration. PCI DSS 4.0 emphasizes logging and monitoring access to cardholder data, while DORA focuses on ICT risk management, operational resilience, and testing for financial entities. In practice, de-identification that cannot show what changed, when, and under which configuration creates audit friction.
- Deployment constraints: For many large banks and payment processors, data cannot leave the controlled environment. Regulated institutions increasingly adopt managed services like Confluent Cloud, Amazon Managed Streaming for Apache Kafka (AWS MSK), or hybrid sovereign cloud deployments. Even so, the de-identification layer itself often must run on-premise or air-gapped, particularly under national data sovereignty rules, EBA/ECB outsourcing expectations, or contractual customer requirements. DORA itself does not mandate data residency, but its Articles 28 to 30 third-party risk obligations, alongside the Article 12 requirement to keep backups segregated from primary systems, raise the bar for keeping the de-identification layer inside the controlled environment.
About DATAMIMIC
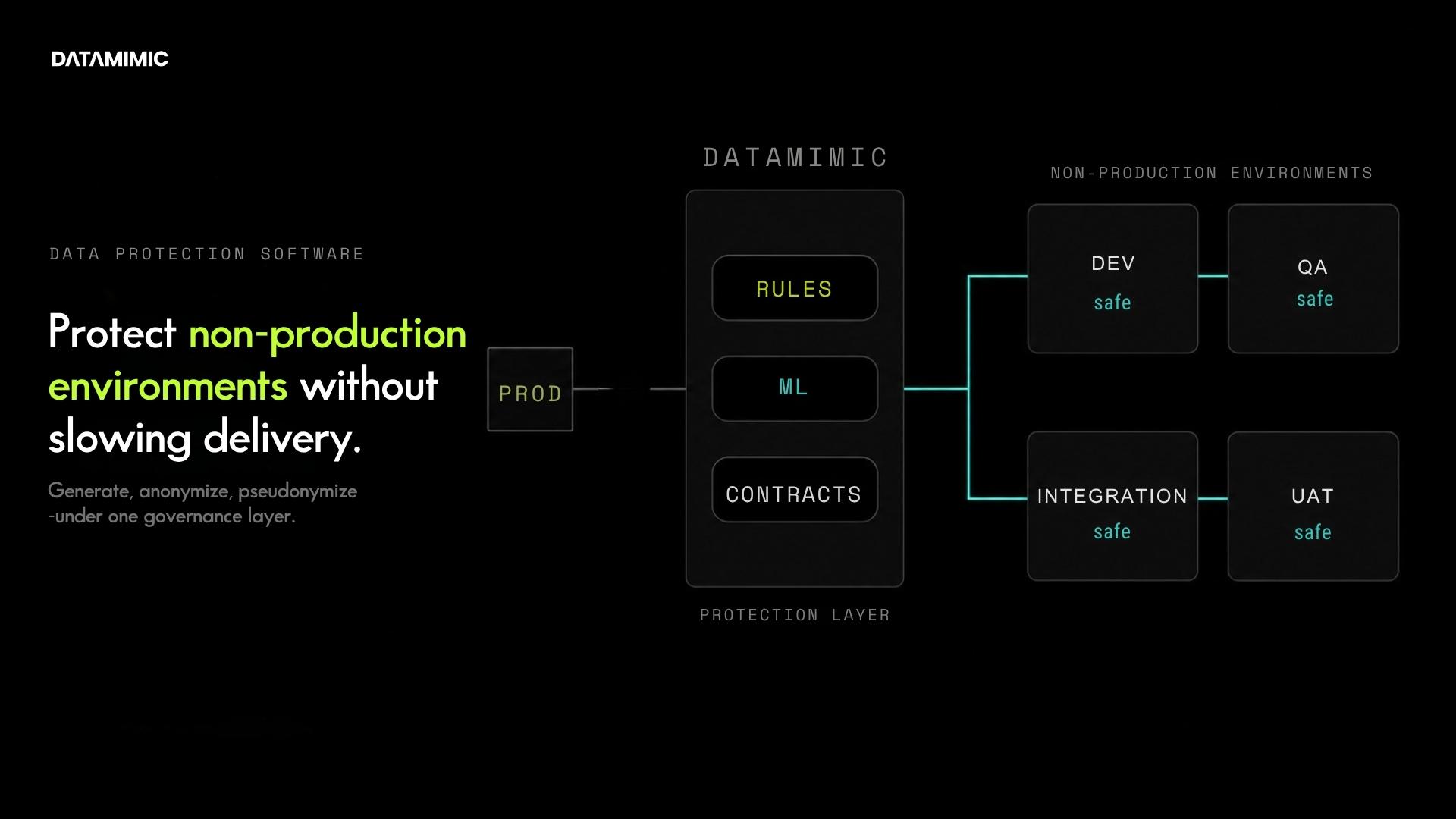
DATAMIMIC is a model-driven, deterministic-first test data platform for regulated enterprises in banking, insurance, and the public sector. It addresses the requirements outlined above through four capabilities:
- Declarative, user-defined generation rules: PCI-governed fields (PAN, IBAN, SWIFT MT fields) are pseudonymized using model-as-code generators with deterministic seeds. Teams define their own generation rules in a domain-specific language rather than picking from a fixed list. By default the model’s
rngSeedis the key, so the same seeded model and engine version produce byte-identical output across hosts and across time, independently verifiable through deterministic seeding and content hashing. For stronger separation, an optional per-environment key, held in the DATAMIMIC platform store rather than in the model, makes identifier tokens irreversible without it and unlinkable across environments. - Cross-topic referential integrity. Pseudonymized identifiers stay consistent across multiple Kafka topics through model-based generation. When a customer ID is pseudonymized in payments, the same pseudonym appears in orders, events, and any downstream consumer.
- Audit contracts with no silent fallback. Every generation run is logged with task ID, model and engine version, and content hash. Two cases, two behaviours: when a required pseudonymization proof is malformed or a mandatory resource is missing, the operation fails closed and the run aborts with a typed error; when an optional resource is absent, the engine degrades through an explicit, logged path. No data is masked through a default path the operator did not approve.
- On-premise, air-gapped deployment. Deployable in air-gapped environments via Helm chart or Podman. No outbound telemetry, no phone-home, no mandatory external connectivity or cloud dependencies.
ACI Worldwide (a global payment processing software provider serving banks, merchants, and billers worldwide) used DATAMIMIC for model-driven, real-time anonymization and pseudonymization of streaming Kafka payment data, applying customer-defined per-field rules across 140 to 180 fields. Each field followed ACI’s own specification: left untouched, hashed with a designated algorithm, or anonymized. The full ACI Worldwide case study is available at datamimic.io/case-study/aci-worldwide.
Getting Started
For architects and engineers: technical documentation at docs.datamimic.io covers Kafka connector configuration, model-based generation, and API integration. The DATAMIMIC Community Edition is a separate, MIT-licensed Python library and CLI (pip install datamimic-ce), published on GitHub and PyPI. CE shares the DSL and determinism contract with the Enterprise Platform and runs locally with no Workbench, PII scanner, scheduler, or governance layer.
CE is the proof vehicle for the determinism claim in this article. The Enterprise Platform is the operational layer regulated enterprises buy on top of it, and is what runs the Kafka multi-process path described above.
Verify the Determinism Primitive Yourself
You do not need to trust our audit log. This check proves the deterministic generator core that the masking pipeline calls. The distributed Kafka masking path is the same primitive under coordination, described in the architecture and audit log above. Community Edition is MIT-licensed and the check runs on any laptop with Python 3.11+. The model below generates one trading session of three correlated stock tickers (AAPL, MSFT, GOOG), 390 one-minute Wiener-process ticks each, with a U-shaped intraday volume profile, all in the DSL. Run twice, hash both output files, compare. Identical SHA-256 means byte-identical output.
# 1. Install CE. Separate library from the Enterprise Platform,
# same DSL, same determinism contract.
pip install datamimic-ce
# 2. Write the model. Time-series is a CE 3.0.0 primitive:
# start/end/interval on <generate>. Per-tick randomness is keyed
# to position (k) and a model-defined seed (1001, 2001, ...).
cat > ticks.xml <<'XML'
<setup>
<generate name="ticks"
start="2024-03-15T09:30:00"
end="2024-03-15T16:00:00"
interval="PT1M"
target="CSV">
<variable name="market" script="sum([random.Random(k*13 + 1001).gauss(0,1) for k in range(ts.step+1)])" />
<variable name="aapl_idio" script="sum([random.Random(k*17 + 2001).gauss(0,1) for k in range(ts.step+1)])" />
<variable name="msft_idio" script="sum([random.Random(k*17 + 2002).gauss(0,1) for k in range(ts.step+1)])" />
<variable name="goog_idio" script="sum([random.Random(k*17 + 2003).gauss(0,1) for k in range(ts.step+1)])" />
<variable name="u_shape" script="math.exp(-((ts.step-10)**2)/2000) + math.exp(-((ts.step-380)**2)/2000)" />
<key name="timestamp" script="ts.now.isoformat()" />
<key name="aapl_price" script="round(180.00 + 0.10 * market + 0.05 * aapl_idio, 2)" />
<key name="msft_price" script="round(420.00 + 0.25 * market + 0.12 * msft_idio, 2)" />
<key name="goog_price" script="round(150.00 + 0.08 * market + 0.04 * goog_idio, 2)" />
<key name="aapl_volume" script="int(80000 + 50000 * u_shape)" />
<key name="msft_volume" script="int(60000 + 35000 * u_shape)" />
<key name="goog_volume" script="int(40000 + 25000 * u_shape)" />
</generate>
</setup>
XML
# 3. Run twice. --task-id pins the output directory.
datamimic run ticks.xml --task-id run-a
datamimic run ticks.xml --task-id run-b
# 4. Hash both output files. They must match.
shasum -a 256 output/run-a/ticks.csv output/run-b/ticks.csv
Expected output:
3e485f22143a0ea6c6fb46a0fb7faac0dc1ead2c57460a53a978ccc4364085aa output/run-a/ticks.csv
3e485f22143a0ea6c6fb46a0fb7faac0dc1ead2c57460a53a978ccc4364085aa output/run-b/ticks.csv
Same CE version, same model, same seed: same hash on your machine, on CI, on a colleague’s laptop. Change any seed constant in the model (1001 → 9999) and the hash changes by construction. That is the GDPR Art. 25 / Art. 32 reproducibility guarantee expressed as a one-line check. It is not a property of the surrounding masking pipeline but of the generator core that the pipeline calls. Statistical or resampling-based synthetic data tools cannot produce a matching pair of hashes by construction.
How the seeding works in the model above
Each tick’s randomness is keyed to its position in the session (k) and a model-defined seed (1001, 2001, …). No shared generator, no worker state. That is what makes the output reproducible across machines, retries, and parallel workers. For DSL-native random patterns (values=, weighted draws, entity generators), <setup rngSeed> at the model root governs the same effect. The inline random.Random(...) pattern shown above is the escape hatch for hand-rolled statistics: Brownian motion, GARCH-style models, anything with custom shape, all without leaving the determinism contract. This is the CE single-process mechanism; the EE multi-process path keys on record content and position as described above. Same contract, two layers.
The block above is the single-process check that covers regression replay and audit re-execution. Cross-worker positional row-keying extends this to Kafka and other multi-process targets, so that a 1-worker CI run and an N-worker production run yield the same per-record output. This is the Enterprise execution layer described earlier.
For decision-makers: the ACI Worldwide case study documents how real-time Kafka anonymization and pseudonymization were implemented for a global payment processor.
If your team is working on streaming data compliance for payment pipelines and struggling with cross-topic consistency or audit traceability, reach out and we’ll walk through the architecture.
FAQ
How do you anonymize PAN data in Kafka without breaking referential integrity across topics?
Cross-topic referential integrity requires the same input to produce the same pseudonymized output across every topic where it appears. Stateless approaches like HMAC-based pseudonymization with a shared key achieve this for single fields. Domain-specific cases such as IBAN check digits, SWIFT field lengths, and EDIFACT segments need rule-based generators that preserve structural validity while keeping the mapping deterministic across the entire event stream.
Is format-preserving encryption the same as tokenization for PCI DSS?
No. Format-Preserving Encryption (FPE) is reversible with the correct key, which keeps the data in PCI DSS scope depending on key management. Tokenization replaces values with surrogates that are non-reversible outside a controlled boundary, which can take the data out of scope. Both preserve format. They differ in reversibility, scope implications, and audit treatment.
Can you delete data from a Kafka topic to comply with GDPR right-to-erasure?
Kafka log records are append-only and cannot be edited in place, so erasure usually requires one of three mechanisms: log compaction with tombstone records for keyed topics, crypto-shredding by destroying encryption keys for already-replicated messages, or rebuilding the topic from compliant sources. DATAMIMIC supports the third path with deterministic regeneration of compliant synthetic streams.
How do you generate consistent test data for Kafka payment topics?
In DATAMIMIC, a single generate block can write to multiple targets in one run: Kafka, MongoDB, JSON, CSV, or any combination. The model is the source of truth; targets are projections of it. Identifier fields are pseudonymized with value-keyed converters, so the same value resolves to the same token in every sink and every topic, byte-identical across all of them:
<!-- One model, three sinks. rngSeed=42 fixes the generated field values and is
byte-identical per record across runs and across numProcess topologies.
Identifier de-identification runs on top via value-keyed converters: Hash
pseudonymizes, MiddleMask partially masks. The token is a function of the
input value, so the same value yields the same token in every topic and every
sink -- customer_token stays referentially consistent across payments.v1, the
JSON file, and the log. -->
<setup numProcess="10" rngSeed="42">
<kafka-exporter id="kafkaSsl" topic="payments.v1"/>
<generate name="payment_event" count="30000000"
target="kafkaSsl,JSON,LogExporter">
<variable name="person" entity="Person"/>
<key name="customer_token" script="person.email" converter="Hash"/>
<key name="customer_name" script="person.name" converter="MiddleMask"/>
</generate>
</setup>
No coordination layer, no re-keying, no downstream join logic. The Kafka topic, the JSON file, and the log receive the same record stream from the same model.
What does a deterministic test data run actually prove for a regulator?
Two layers of evidence, intentionally separated:
Layer 1: mathematical reproducibility (Community Edition, independently verifiable). Each run is logged with task ID, engine version, planned-vs-exported counts, and timing per statement:
DATAMIMIC CE lib version: 3.0.0
Task ID: 9f5d61e7-f125-441e-a775-cd99c55c7b7e
Generating 10000 records 'payment_event' took 0.14s (71,429 records/sec)
Saving exported result for product payment_eventPair that with a SHA-256 of the output and you have a proof a regulator or counterparty can re-run without touching DATAMIMIC infrastructure: same model, same seed, same hash, every time. The 30M-record Kafka case is the Enterprise execution layer (Layer 2 below); CE proves the per-record math at a scale anyone can re-run on a laptop. Statistical or resampling-based synthetic data tools cannot produce this match by construction.
Layer 2: operational audit evidence (Enterprise Platform). EE adds structured, runtime-profile-controlled observability that production-scale audit requires:
- Typed user errors with stable issue codes and documentation links so a failed run resolves to a single docs page, not a stack trace.
- Structured CONTROL and HEALTH lines with stable keys for machine parsing:
# illustrative run record
FASTOPS | rust=enabled
CONTROL | kind=start | descriptor=datamimic.xml | pid=13849
HEALTH | client=kafka | type=kafka | status=ok | latency_ms=12
CONTROL | kind=execution_plan | stmt=payment_event | source_partition_owner=data_source | paging_strategy=data_source_sharding
EXPORT | coordinator | instance=f10abec9 | start=0 | end=30.000.000 | workers=10 | worker_id=1
PROGRESS | stmt=payment_event | scope=worker | worker=1 | 100% | exported=30.000.000 | 72,762 rec/s
Summary | payment_event: planned 30.000.000 · exported 30.000.000 in 412.31s (72,762 rec/s)
CONTROL | kind=stmt_end | stmt=payment_event | status=ok
CONTROL | kind=end | status=ok- Rate cards that surface the planned read strategy and source/target capacity profile per statement, so a slow consumer or rate-limited datasource shows up in the run record, not in an SRE post-mortem:
CONTROL | RATE_CARD | rc_ver=1 | backend=kafka | strategy=batch_pull
| stmt=payment_event | selector=topic | throughput=high
| src_cpu=low | src_io=net_bound | temp=0 | resume=exact- Per-stage granularity, configurable per runtime profile (Performance, Balanced, Flexibility). The runtime config exposes named knobs the auditor can pin in the run record: log_nested_progress, log_nested_summaries, ds_log_source_metrics, ds_log_export_metrics, log_stmt_start, log_debug_stacktraces, log_progress_pct, and others. Different profiles, different verbosity, same line grammar.
- Fail-closed-or-degrade with full logging in either direction: malformed mandatory proofs abort with a typed error; absent optional resources degrade through an explicit, logged path. No silent fallback either way.
Layer 1 is what your team and a regulator can verify independently. Layer 2 is the operational record that closes the loop for PCI DSS 4.0 logging requirements and DORA traceability expectations at production scale.