Home › The 5 best MOSTLY AI alternatives for enterprise test data 2025
The 5 best MOSTLY AI alternatives for enterprise test data 2025
In the world of enterprise software development, high-quality, privacy-safe test data is gold. While MOSTLY AI is a powerful platform for generating synthetic data, it’s not the only solution on the market. Whether you’re seeking different features, more flexible pricing, or better integration with your existing tech stack, exploring alternatives is crucial. This post dives into the five best MOSTLY AI alternatives to help you find the perfect fit for your enterprise test data needs.

I. The New Data Imperative: Statistical Accuracy Meets Ironclad Privacy
In today’s data-driven economy, using high-quality test data is not just helpful; it is, in fact, required for innovation. However, this creates a big problem for companies in fields like finance and healthcare. On one hand, the demand for realistic, production-like data to train AI models and rigorously test applications has never been higher. Yet, strict privacy laws like GDPR, CCPA, and HIPAA have made using raw production data risky. For example, the average cost of a data breach rose to $4.45 million in 2023. Ultimately, this shows the financial and reputation risks involved.
As a result, this tension has fueled the explosive growth of the synthetic data market. Projections show that by 2030, synthetic data will completely overshadow real-world data for developing AI models. In addition, the broader Test Data Management (TDM) market is forecast to expand to between $2.1 billion and $3.87 billion by 2033, with a CAGR exceeding 10.8%. Clearly, this growth isn’t just about creating more data; it’s about creating smarter, safer synthetic data.
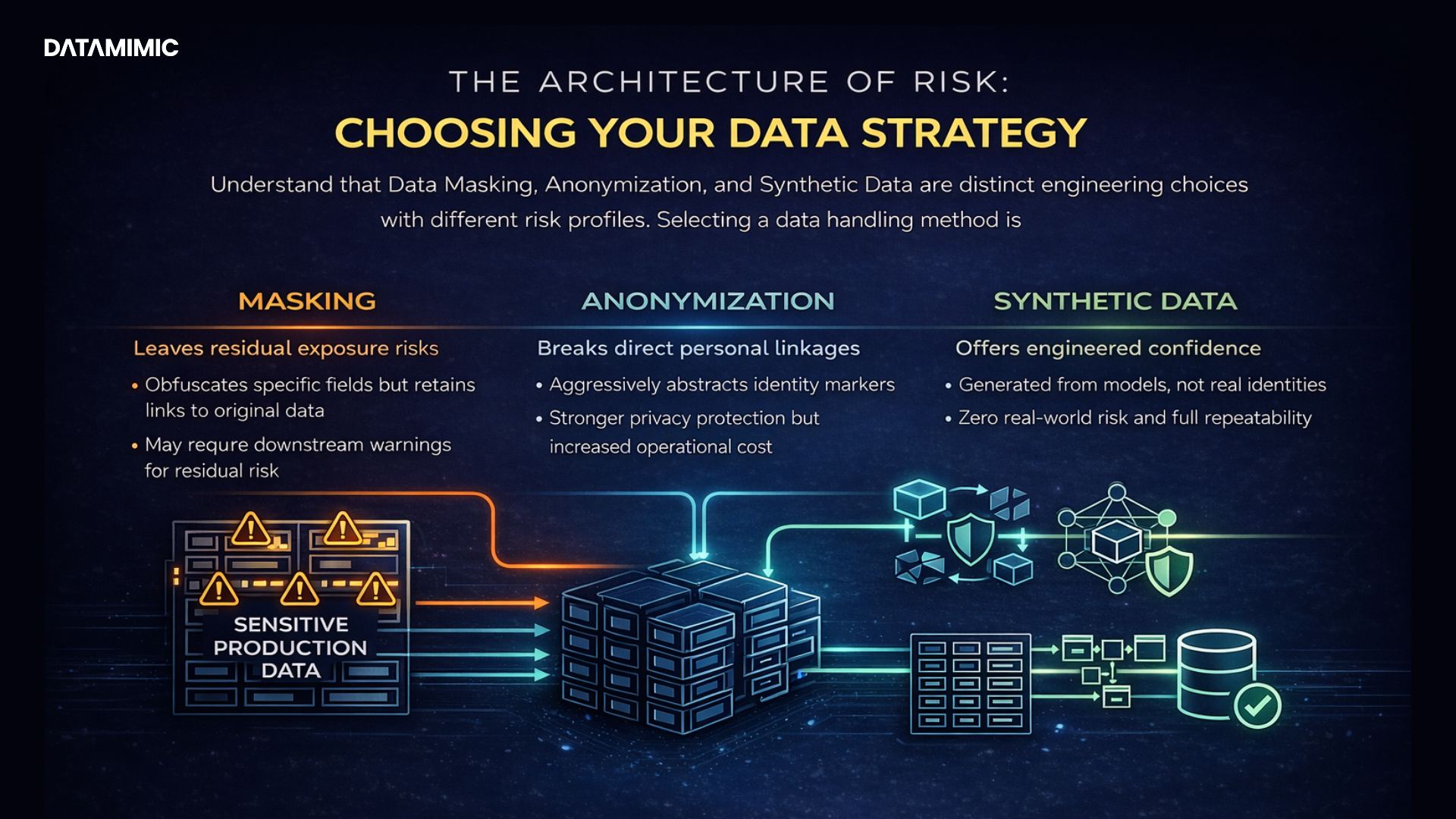
Consequently, the conversation has changed from simple data masking to a more advanced method. This method uses Generative AI to create new, artificial synthetic datasets. Crucially, these datasets are statistically the same as real-world data. This process is called Test Data Generation. It is a revolutionary method. Ultimately, it gives data scientists and QA teams synthetic data that acts like production test data. This data does not contain any personally identifiable information (PII). This privacy-by-design method is becoming very important. It allows fast development, strong AI model training, and easy data sharing across departments and countries. Furthermore, it avoids the long delays and compliance problems that come with using production data. More than 72% of teams use AI-driven testing workflows. Therefore, the quality, accuracy, and safety of test data are now the foundation of competitive advantage.
II. A Quick Look at MOSTLY AI: Strengths and Common Gaps
MOSTLY AI is a leader in the synthetic data field. It supports using Generative AI to create high-quality, privacy-safe synthetic data. Its platform works by training deep machine learning models on real data. These models learn the data’s patterns, distributions, and connections. Then, the platform creates a new, artificial synthetic dataset that matches these properties.
1. Key Strengths of MOSTLY AI
- Statistical Accuracy: The platform’s core strength is its ability to produce synthetic data that is statistically identical to the original, making it a powerful proxy for analytics and AI/ML model training.
- Privacy by Design: Through its data generation process, MOSTLY AI eliminates the one-to-one links to real individuals found in traditional anonymization, effectively removing re-identification risk when creating synthetic datasets and ensuring compliance with regulations like GDPR.
- Ease of Use for Data Scientists: The platform is designed to be accessible, allowing users to synthesize entire databases without needing to write code or perform complex hyperparameter tuning for their machine learning projects.
- Versatility in Use Cases: From AI training and bias mitigation to product development and testing, MOSTLY AI’s platform is highly versatile and has been adopted by major players in finance, insurance, and telecommunications to improve their machine learning models.
2. Why Look for a MOSTLY AI Alternative for Test Data Generation?
MOSTLY AI is good at creating statistically accurate data. However, modern companies have many different needs, and a one-size-fits-all method is rarely the best choice. For this reason, teams often seek alternatives for several key reasons, often driven by challenges like data scarcity where not enough real data exists to train a model effectively.
Need for Rule-Based Control
MOSTLY AI’s approach is to learn from data. On the other hand, many testing scenarios, particularly for performance and edge-case software testing, require data that follows specific, predefined rules that may not exist in the source data. Consequently, a rule-based engine offers superior control over data generation, a contrast to open-source tools like the Synthetic Data Vault.
Handling Highly Complex Data Structures
While excellent with tabular data, the data generation of deeply nested and complex JSON or XML files for modern software testing and testing NoSQL databases can be a challenge for sample-based AI models. Therefore, specialized tools often provide more granular control over these formats.
Hybrid Use Cases (Masking & Generation)
Furthermore, many enterprises don’t operate in a purely synthetic world. Instead, they often need to de-identify or mask existing production test data, a feature where other platforms specialize and offer more advanced capabilities.
Performance and Integration in CI/CD
Likewise, for high-velocity DevOps environments, the speed of on-demand data generation and seamless integration into CI/CD pipelines are paramount. Some alternatives are purpose-built with a high-performance core to meet these specific demands, offering a different value proposition than libraries like the Synthetic Data Vault.
Cost and Complexity
Finally, user feedback suggests that while powerful, the platform can have a complex setup process and a high price point, particularly for smaller businesses or teams just starting their synthetic data journey.
III. The Top 5 MOSTLY AI Alternatives for Enterprise Teams
For organizations whose requirements demand a different approach, the market offers a range of powerful and specialized alternatives. Here are the top five contenders.
1. DATAMIMIC: The High-Performance Engine for Complex Data & Agile Development
DATAMIMIC is designed for fast and complex modern cloud-native software development. It solves testing problems for microservices, NoSQL databases, and applications. It works well in fast Agile and Test-Driven Development (TDD) cycles.
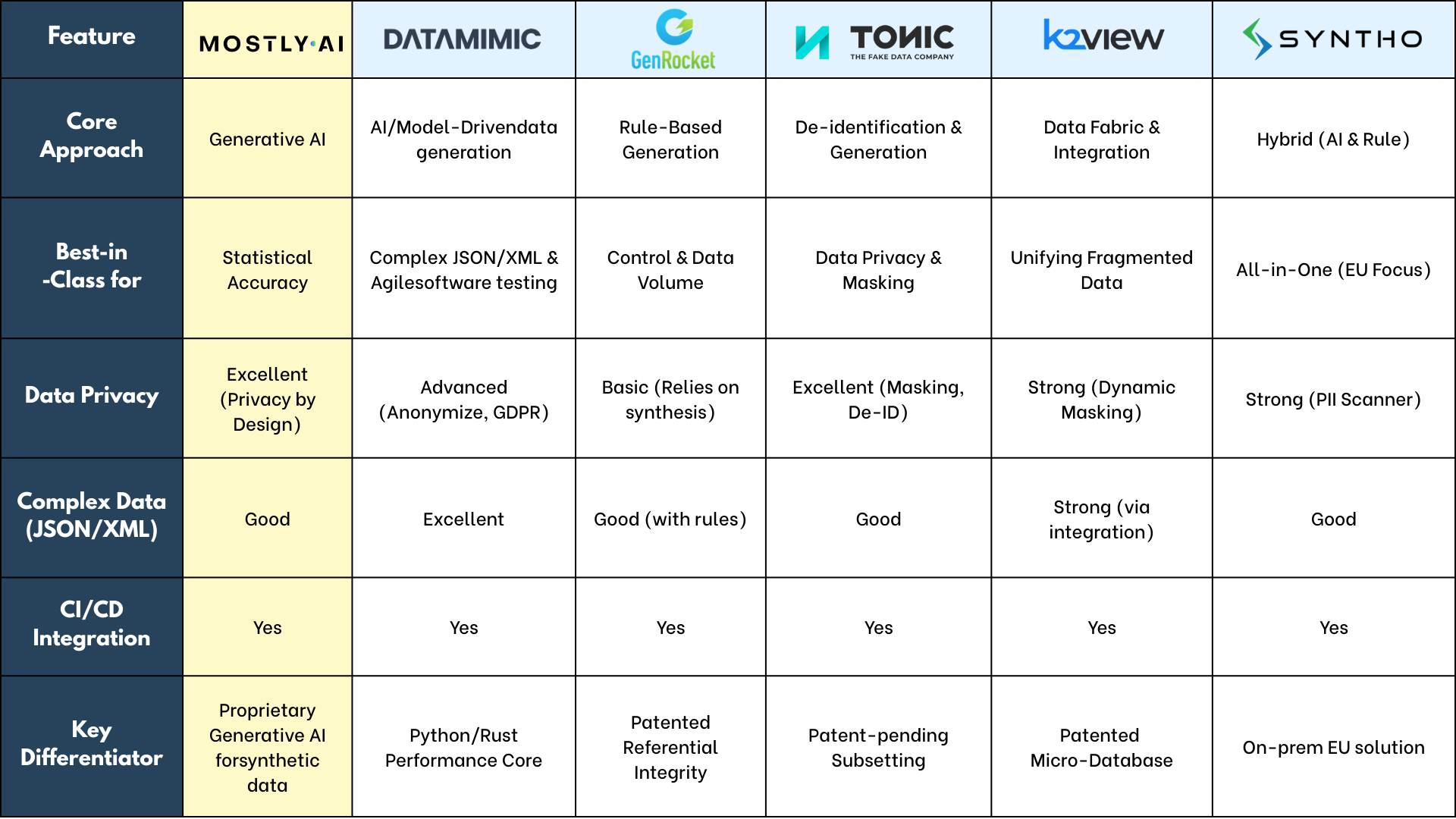
- Core Approach: DATAMIMIC employs an AI- and model-driven methodology. Instead of learning from a data sample, it allows users to define data requirements at an abstract level, after which its intelligent engine generates data to fit the model.This provides immense flexibility, especially when production data doesn’t yet exist, making it a powerful tool for data generation.
- Key Differentiator: Its mastery of complex, nested JSON and XML is a standout feature for any test data generator. The platform can ingest a schema and use powerful templates with custom scripts to precisely replicate the intricate data structures common in microservices architectures, a key advantage over platforms optimized for tabular data.
- Performance: Built on a dual-technology core of Python for its AI libraries and Rust for its speed and reliability, DATAMIMIC is architected for high-performance data generation, designed to integrate seamlessly into demanding CI/CD pipelines.
- Privacy & Compliance: The platform offers robust anonymization and pseudonymization features, ensuring full GDPR compliance while providing safe, realistic test data for development and testing.
- Best For: Enterprises practicing Agile/TDD and building applications with microservices or NoSQL databases. It is the ideal choice for teams that need a high-performance, intelligent engine to generate complex synthetic data on-demand.
2. GenRocket: The Rule-Based Powerhouse for Control and Scale
GenRocket uses a very different method to create synthetic data. Where MOSTLY AI learns from data, GenRocket follows explicit instructions, giving teams absolute control over the Test Data Generation they create.
- Core Approach: GenRocket uses a sophisticated, component-based architecture to generate data based on user-defined rules.This allows testers to create any test data scenario imaginable, including negative test cases and specific edge conditions that are often missing from production data.
- Key Differentiator: Its U.S. patent for maintaining referential integrity across multiple databases is a mission-critical feature for testing complex relational systems.It is a performance leader for structured data, capable of generating thousands of rows per second on modest hardware.
- Strengths: GenRocket excels at generating massive data volumes for performance and load testing.Its self-service portal empowers testers to design and deploy data on-demand, and it consistently receives top marks for customer support.
- Best For: Organizations that require granular control over their test data, need to generate very high volumes of structured data for performance testing, and must maintain strict referential integrity across complex relational databases.
3. Tonic.ai: The Specialist in De-identifying Production Data
Tonic.ai is the top solution for companies that want to keep their existing test data safe. They want to make this data easy to use for developers and quality assurance teams. They do not want to create data from scratch.
- Core Approach: Tonic.ai’s suite of products- Tonic Structural, Tonic Fabricate, and Tonic Textual—focuses on data de-identification, masking, and subsetting.It creates a high-fidelity, de-identified version of your production database that preserves its utility for testing.
- Key Differentiator: Its best-in-class privacy features for synthetic data are its core strength, consistently earning high scores from users.Its patent-pending technology for database subsetting allows teams to create smaller, targeted, yet referentially intact datasets for specific testing needs.
- Usability: Users often report a more intuitive setup process compared to other enterprise tools, and its transparent pricing model makes it accessible for teams of all sizes.
- Best For: Companies in highly regulated industries like financial services and healthcare that need to safely leverage their production data. It is the perfect choice for teams that prioritize de-identification, masking, and subsetting over purely generative capabilities.
4. K2View: The Enterprise Data Fabric for Unifying Siloed Systems
K2View addresses a more fundamental problem: for many large enterprises, the test data challenge is a symptom of a larger data integration problem. Effective Test Data Management is one of several use cases powered by this unified data layer.
- Core Approach: The K2View Data Product Platform packages data from multiple sources into reusable “data products”.
- Key Differentiator: Its patented Micro-Database™ technology is a unique architectural advantage for Test Data Generation. For each business entity (e.g., a customer), the platform creates a single, encrypted, and continuously synced micro-database, providing a trusted 360-degree view.
- Strengths: K2View excels at data integration and offers robust data masking capabilities.It’s a comprehensive platform for organizations looking to build a modern data fabric to serve multiple business needs, including TDM.
- Best For: Large enterprises with complex, fragmented data landscapes and legacy systems. For these organizations, K2View offers a strategic solution to their core data integration challenges, with test data management as a key benefit.
5. Syntho: The Flexible All-in-One Platform with a European Focus
-
- Core Approach: Syntho provides a flexible, hybrid platform that combines AI-generated synthetic data, smart de-identification, and traditional rule-based data generation.This allows teams to select the optimal method for each specific use case.
- Key Differentiator: Its strong focus on GDPR compliance, including an AI-powered PII scanner, makes it a trusted choice for European companies.It also offers on-premise deployment, a critical feature for organizations with strict data residency requirements.
- TDM Features: The platform includes a full suite of TDM functionalities, such as database subsetting and rule-based Test Data Generation, making it a comprehensive, all-in-one solution.
- Best For: European enterprises, or any organization with a strong focus on GDPR, looking for a flexible, all-in-one data platform that offers a hybrid approach to data generation and can be deployed on-premise.
IV. A Strategic Guide to Choosing Your Data Platform
The ideal synthetic data tool is not the one with the most features, but the one that solves your most critical business problem. The choice reflects your organization’s architecture, compliance posture, and software testing methodology. Use these scenarios to guide your selection:
- If your primary need is to create statistically perfect, anonymized datasets for AI training and analytics… then MOSTLY AI‘s generative AI approach is the industry standard and an excellent choice.
- If you need absolute, rule-based control to generate massive volumes of structured data with perfect referential integrity… then GenRocket‘s powerful and precise engine is unmatched.
- If your main task is to make your existing production data safe for developers while preserving its realism… then Tonic.ai‘s best-in-class de-identification and masking capabilities are your most direct solution.
- If your test data issues are a symptom of a much larger data integration problem across siloed systems, then a foundational data fabric platform like K2View will address the root cause.
- However, if your teams are building the next generation of software—cloud-native, microservices-based applications that rely on complex data formats—and you need a data engine that matches your agile velocity, then a high-performance, AI-driven synthetic data generation platform purpose-built for this modern paradigm, like DATAMIMIC, is the most strategic investment. It is designed from the ground up to handle the complexity and speed that other data generation techniques are not.
V. Your Data Should Accelerate, Not Obstruct, Innovation
The era of treating Test Data Generation as an afterthought is over. In a world driven by AI, machine learning, and rapid development cycles, test data is a first-class citizen in the SDLC. Relying on slow, manual processes or a tool that doesn’t fit your core challenge for synthetic data creates a bottleneck that negates investments in DevOps and automation.
Generative AI platforms like MOSTLY AI have led the way in making synthetic data that is statistically accurate and private. But future application development needs more than this. It requires a solution that not only understands data privacy but also masters synthetic data complexity and operates at the speed of modern CI/CD pipelines. DATAMIMIC stands out as the platform built for this future, combining a powerful AI- and model-driven approach with a high-performance core engineered to master the complex test data demands of today’s most innovative enterprises.
Your pipeline’s velocity should be defined by your team’s creativity, not constrained by your data’s availability. Learn how DATAMIMIC’s smart platform can remove your test data problems. It can speed up your development process.
Request a personalized demo of DATAMIMIC today.

Alexander Kell
August 19, 2025
Contact Us Now
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly