Home › Data masking vs anonymization vs synthetic data: what actually reduces risk?
Data masking vs anonymization vs synthetic data: what actually reduces risk?
For regulated teams, the debate around data masking and anonymization is no longer academic. It is not a side topic for legal review or a theoretical discussion reserved for policy teams. It now sits directly inside release speed, audit exposure, and customer trust. Every decision about how data is handled in non-production environments can affect how fast teams test, how confidently they ship, and how well they stand up to compliance scrutiny.
For engineering, QA, and platform teams, the risk goes beyond direct exposure of sensitive data. It also includes slower delivery cycles, stale test environments, weak edge-case coverage, and systems that drift apart as schemas evolve. Those problems may look operational at first, but they quickly turn into quality and compliance issues when teams can no longer trust the data they are testing with. In heavily regulated sectors, the right approach has to support both security & compliance and practical software delivery.
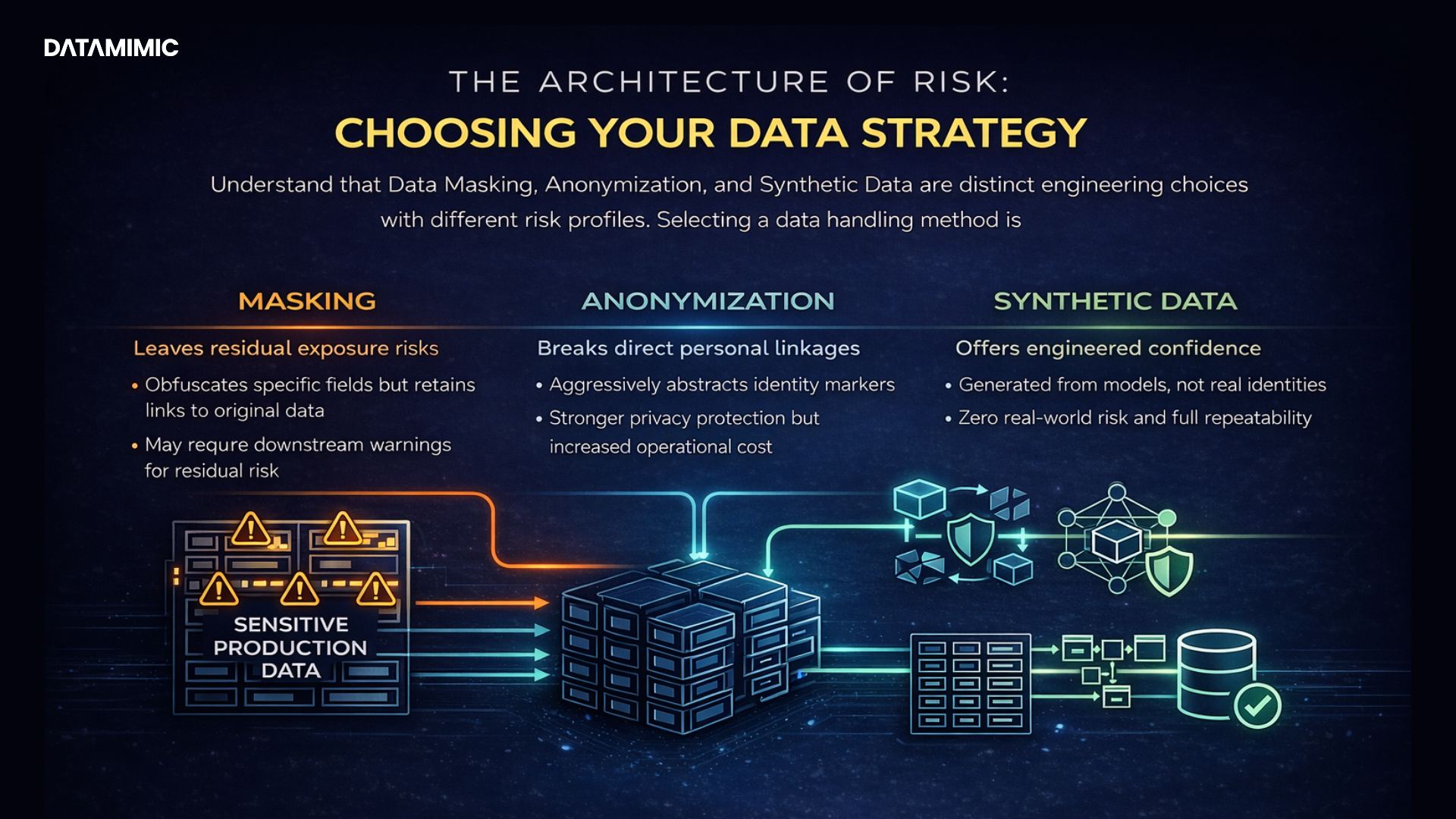
Production data masking helps, but it does not remove every risk?
Production data masking is still widely used across the data industry, especially in organizations that need quick access to production-like structure without exposing the most obvious identifiers. In practice, it usually starts with real records and applies data masking techniques, data masking methods, or specific masking rules to hide selected values such as names, account numbers, addresses, or other sensitive fields. Some teams also rely on predefined masking algorithms to transform values consistently across environments.
This approach can reduce the direct exposure of user data, personally identifiable information, and other forms of sensitive information inside lower environments. That is one reason many teams still rely on masking in day-to-day delivery workflows. It can help limit access to the most obvious identifiers while preserving enough structure for certain testing and operational tasks. In payments environments, that matters because teams often work under strict data protection expectations and framework-driven controls such as PCI DSS. As a result, masking remains a familiar part of many security & compliance programs.
Still, familiarity should not be confused with completeness. Masking can reduce exposure, but it does not always remove the underlying privacy, governance, or maintenance burden. That means the original privacy and governance burden does not disappear simply because selected fields have been obscured. In many cases, masked data remains linkable, especially when the dataset still preserves structure, relationships, or business context. A name may be hidden, but patterns in the record can still reveal more than teams expect. That is why teams often underestimate the remaining data protection and regulatory compliance obligations.
Why anonymization has a higher bar than masking?
Anonymization is different because the goal is not simply to hide visible identifiers. The goal is to make sure a record cannot reasonably be linked back to a person. That is a much higher bar than replacing names or partially obscuring values in selected columns. It changes the question from “Can we hide the obvious details?” to “Can this record still be tied to an individual through context, structure, or combination with other information?”
That distinction matters for both privacy regulations and internal data privacy compliance. In practice, many teams say data is “anonymized” when what they really mean is “masked” or “pseudonymized.” The language sounds similar, but the compliance meaning is not the same. When those terms are used loosely, delivery teams can end up making decisions based on the wrong assumption about how protected the data really is.
If your non-production environment still depends on transformed versions of real customer records, masking may not remove the privacy risk completely. You may still be handling personally identifiable information. In other words, applying masking does not automatically mean the data is no longer sensitive.
This matters even more in healthcare. In that sector, protected health information is governed by HIPAA standards. It is also critical in financial services, where teams operate under strict data privacy regulations and broader regulatory requirements. In both cases, the difference between masking, anonymization, and synthetic data has real compliance consequences.

Synthetic vs masking: where the risk profile changes
This is where synthetic vs masking becomes a practical engineering decision.
A strong masking alternative does not begin with copied production identities and then transform selected fields after the fact. That older pattern still keeps real customer records at the center of the workflow, even if certain values are hidden. Synthetic data generation changes that starting point. Instead of modifying existing production records, it creates new data from models, schemas, and rules.
That is why model-driven synthetic generation matters more than simple “fake-looking data.” The real value is not that the output appears realistic at first glance. The value is that teams can generate data that follows structure, respects business rules, and stays useful across different systems and testing scenarios. With the right approach, synthetic data generation makes it possible to create realistic and repeatable datasets without depending on copied customer identities as the default starting point.
But not all synthetic data is equal. If it ignores business rules, misses important edge cases, or breaks referential integrity, it can still fail as test data even if it looks safe from a privacy perspective. Good synthetic test data is valuable because it remains structurally reliable across systems, contracts, and workflows. Teams need data that behaves correctly in databases, APIs, and downstream validations, not just data that appears realistic in isolation.
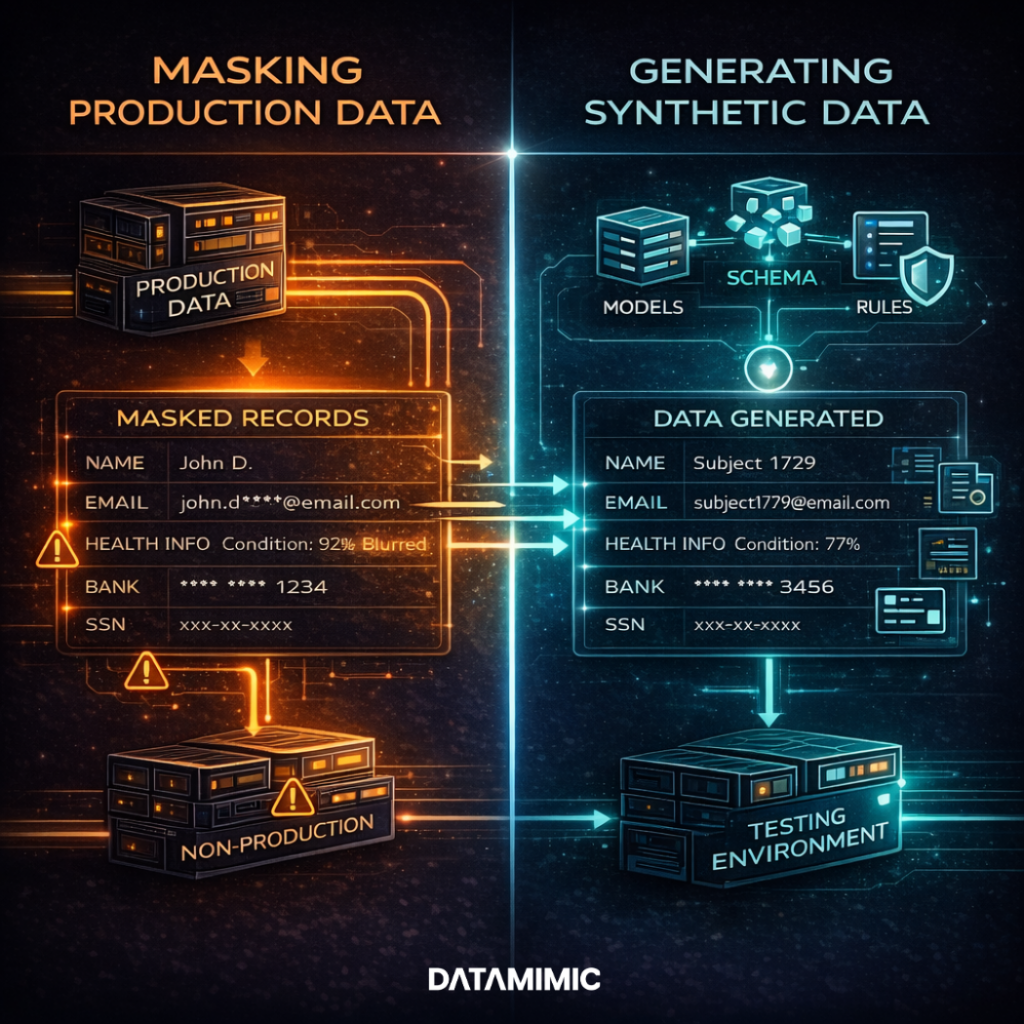
Which method reduces privacy, compliance, and delivery risk most effectively?
The honest answer is that different methods reduce different risks.
If real data must continue moving through live systems, then anonymization or pseudonymization controls may be necessary. In that situation, the goal is not to replace the data entirely. The goal is to reduce exposure while preserving the operational flow that the business still needs to run. That makes it a data protection problem inside live processes. Teams are protecting sensitive information while records or messages continue to move through operational systems.
If teams need a short-term way to reduce exposure in copied lower environments, production data masking may help. Both static data masking and dynamic data masking have a place, depending on whether the need is to transform stored copies or restrict runtime visibility. But they do not fully solve the longer-term problem. As schemas evolve, datasets age, and contracts change, masked copies often need repeated manual fixes to stay usable. Each refresh cycle can turn into another round of repair work, exceptions, and revalidation.
This is the point where privacy enhancing technologies and model-driven test data become much more valuable. When teams keep relying on copied records, they often end up spending time patching old datasets instead of improving the actual quality of testing. A more durable alternative is to generate fit-for-purpose data when it is needed. That data can be aligned to current contracts, current schemas, and current test scenarios. This makes test environments easier to maintain as systems change.
For many teams, copied and masked data still feels familiar because it looks close to production. It resembles the structure and workflow behavior people already know. But familiar is not the same as low-risk. A dataset can look realistic and still carry privacy obligations, maintenance overhead, and hidden quality problems. It can also increase exposure to a broader cybersecurity threat if copied records continue spreading across more lower environments.
At that point, data masking and anonymization are no longer simple checkbox decisions. They become part of a broader strategy for security & compliance. They also affect delivery resilience, operational stability, and your overall exposure to data breaches.

Final takeaway
The teams that reduce risk best do not treat masking, anonymization, and synthetic generation as interchangeable. They ask which method reduces the right risk in the right place.
For live flows, protect real data properly.
For non-production testing, stop relying on copied identities as the default.
That is where synthetic vs masking becomes more than a compliance discussion. It becomes a decision about delivery speed, maintainability, privacy posture, and long-term resilience for regulated engineering teams.
Read the banking case study to see how a Tier-1 European bank moved from masked snapshots to deterministic test data across Oracle, MongoDB, and Kafka.
See How DATAMIMIC Works
Want to see how DATAMIMIC helps teams build deterministic test data workflows with repeatability, rule history, and strong referential integrity across complex systems?
Book a free DATAMIMIC demo to see how model-driven generation works in practice for regulated environments.
FAQ
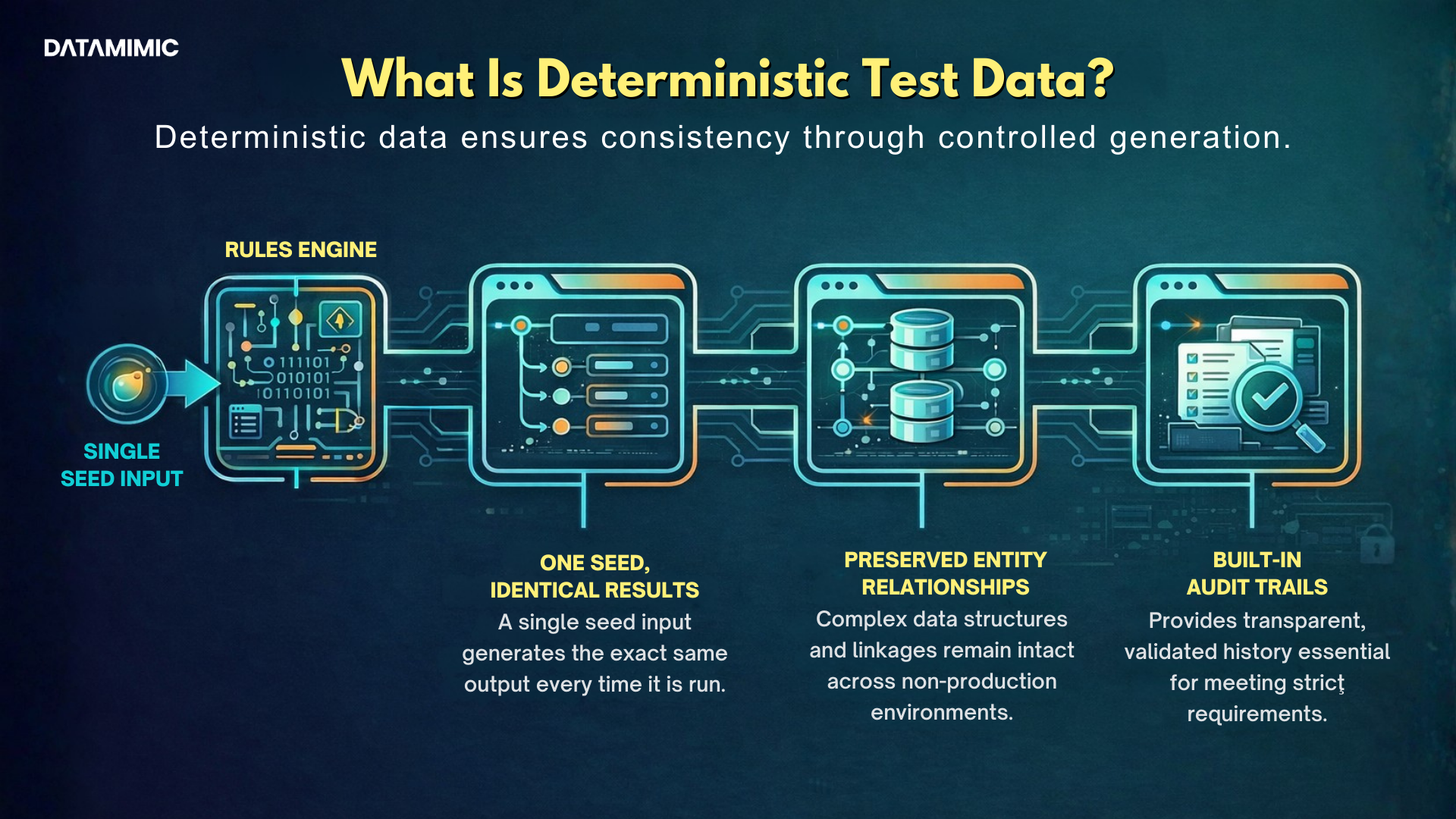
1. What is deterministic test data?
Deterministic test data is test data generated in a repeatable way so that the same rules, inputs, and seed create the same output each time.
2. Why is reproducible test data important for regulated teams?
Reproducible test data helps teams rerun scenarios, investigate failures, support audits, and keep testing consistent across environments and pipelines.
3. Why does referential integrity matter in test data?
Referential integrity ensures that records and relationships remain valid across systems, which is essential for realistic and reliable testing.
4. What is deterministic JSON test data?
Deterministic JSON test data is repeatable structured test data used for nested JSON payloads, APIs, events, and other complex workflows.
5. How is deterministic test data different from masked production data?
Deterministic test data is generated from controlled logic and can be recreated consistently. Masked production data is often harder to maintain, explain, and reproduce over time.

Alexander Kell
March 19, 2026
Contact Us Now
Facing a challenge with your test data project? Let’s talk it through. Reach out to our team for personalized support.
We’ve received your submission and will be in touch shortly